Kaggleの登竜門、タイタニックコンペでいざ実践!
ブログ作成者紹介
Vareal株式会社
名前:Y.C
部署名:データサイエンス部
役職(ポジション):データサイエンティスト
業務内容:データエンジニアリング 大規模言語モデルを使用したプロダクト研究開発支援
趣味:ランニング スポーツ観戦
Kaggle?分析コンペとはなに?
Kaggleってなに?
皆さんは「Kaggle(カグル)」という言葉を聞いたことがあるでしょうか?データ分析に関わる人たちの中ではかなり知られているワードなのですが、そうでない人からしますと一体なんなのかあまりイメージができない響きかもしれません。
Kaggleはざっくりと説明しますと、世界中のエンジニアなどがそのデータ分析力を競い高め合うプラットフォームみたいなものです。分析コンペなんてよく言われます。2017年にGoogleに買収されたというのは一時期話題にはなりましたね。
データサイエンティストやAIエンジニアなら少なくともみなさん一度は挑戦したりしたことはあるのではないでしょうか?そこで切磋琢磨して知見を深めてより高みを目指す人もいれば、自分のように世界の広さを知って、「まあKaggleはしょせんKaggleだからな、業務で通用するかは別問題だしな」と言い聞かせてあまり近づかないという人も少なくないかもしれません。

あの漫画でいうところの天空闘技場!
Kaggleでは日々いろんなコンペ、つまり大会が開かれていますが、成績の上位者には数千~数万ドルの賞金も設定されていて、成績に応じたメダルや実績に応じたランクも付与されます。チームを組んで出場することもでき、日本のとある企業ではこのKaggleにひたすら挑戦し続けるだけの部署なんかもあるとかないとか。自分も賞金獲得のために挑戦しようと何度か参加をしたりしましたが、まず何を分析してどういう出力が期待されているかという、課題の趣旨を把握するのもなかなか難しくそこでまず心が折れることが多いです。そのあとでなんとか美味しい物を食べたりとかしてメンタルを回復させてコンペの内容を把握したところで、参加者がモデルを公開していたり議論をしたりするコミュニティをみて、すでに置いていかれてることを目の当たりにしてまた心が折れてしまいます。そのあとでまたランニングしたり、ボクササイズをしたりして気持ちを作ってコンペに復帰するも、自分の成績とコンペのランキングとの差を感じで、「今回のコンペは相性が悪かったかもなぁ」と自分に言い聞かせて結果そのまま放置するみたいなことなります。世界中のデータ分析自慢の人たちが参加していますのでそれは当然そうなのですが、非常にレベルが高く自分の弱さを思い知らされることがしばしばです。
言ってみると『ハンター×ハンター』のヨークシン編の幻影旅団が出てきた時の絶望感みたいな感じです。自分も旅団側の人間でありたいものですが、残念ながらまだ一般のモブキャラのランクです。せめてあのクロロの手刀を見逃さなかった人くらいではあって欲しいなとは思いたいものですが。・・・『ハンター×ハンター』を知らない人にとってはなんのことかわからないと思いますが、兎にも角にもKaggleというのは、日夜データサイエンティストやAIエンジニア、データアナリストなど、データ分析に関わる人たちがその実力を競い合うプラットフォーム、まさに『ハンター×ハンター』の天空闘技場なわけなんですね。
今回のブログでは、これまでの分析の紹介などを踏まえてその実践編として、Kaggleの中で最も有名であり、まず最初に挑戦する登竜門でもある、タイタニックのコンペに挑戦してみたいと思います!「kaggleってことはコンペだから結局実践じゃないのでは・・?」みたいな声もあるかもしれませんが、まあ細かいことは気にせずにやっていきましょう!
弊社ではデータ分析やデータ可視化のご支援も可能です、もし興味を持っていただけましたらぜひお問い合わせくださいませ!
タイタニックコンペを見ていこう
豪華客船タイタニック
ではまずそのタイタニックのコンペを見ていきましょう!ちなみにコンペ会場のURLはこちらです。
これはもちろん練習用のコンペなので、よい成績を出しても賞金もなければメダルの授与もないですし、ランクなども影響しません。ゲームのチュートリアル的な感じですね。タイタニックというタイトルの通り、あの豪華客船のタイタニックに関するデータのコンペになっています。余裕がある方は上のURLを見ながら見ていただければと思います。言い忘れていましたが、基本すべて英語になります。

Overviewというタブがあるかと思いますがそこをみてどういうコンペでなのか把握するところからまず始まります。そのほかにDataとかDiscussionなどありますが、その名前から連想できる通りのコーナーになっています。最終的な結果は、基本Submissionsのところから提出する形になります。
さて、このタイタニックのコンペの内容ですが、まずtrainデータとして、891人の乗客の色々なデータを頂けます。例えば年齢とか、性別とか、その人のチケット番号とか、どの港から乗ったとかそういったものです。その中に”Survived”というデータもあるのですが、これはその人がタイタニックが沈没した際に生き残れていたか死んでしまったかというのを表すものになっています。
このデータを踏まえて、trainデータとは別の人物の418人の乗客のtestデータが与えられます。このtestデータは、trainデータと基本同じですが、”Survived”のカラムはありません。ということでこのコンペでは、trainデータでモデルを作り、testデータの”Survived”、つまりその乗客が助かったか助からなかったかを推定する二値分類問題というのを行うことになります。生死を推定するということでちょっと残酷な感じもしますが、データの数や種類、その構造などを考えるKaggleにとどまらず、データ分析を勉強中の人やバリバリのデータサイエンティストの方でも知見やスキルアップをする上でとてもよい教材ではあるかと思います。
実際にtrainデータを取り込んで、5行だけ表示してみたデータがこちらです。

少し見づらいかもしれませんが、細かく見ていただく必要はありません。これは「id_5」さんまでですが、先ほどtrainデータは891人の乗客のデータと申し上げた通り、「id_891」さんまであるということになります。ちなみにこの5行では欠損値はないですが、もちろん欠損値は多く存在します。それにどう対処するかもデータサイエンティストの腕の見せ所の一つとなります。加えて、数値じゃないデータもあるがそれはどうするの?使えないんじゃないの?と思う方もいらっしゃるかもしれませんが、これもうまく数値のデータに変換して使用することができます。
このようにしてコンペの内容やデータの概要を把握するのが第一歩となります、『ハンター×ハンター』でいうところでは何なのかと上手く表現したいところではありましたが、あまりよい例が浮かびませんでした。Kaggleを天空闘技場と例えているので、まあここは1階かと考えていいかもしれません。念の習得というステップとはほど遠い状況であることは確かであるかと思います。
データを細かく知ろう
コンペやデータの構造が把握できたところでこの後のステップは人によってまちまちかとは思います、特に正解があるわけではなく何通りも方法はあります。さすがにコンペの内容をちゃんと理解できていないのにいきなりデータを引っ張ってきてモデルを作るという方法はなかなか難しいので上記のステップはまず最初にすべきかとは思います。
次にやるステップとしてよく行われるようなものを簡単に紹介をしていきたいと思います。もちろん、これは今回のタイタニックコンペではということになってまして、コンペには、画像分類、数値予測、生成AI関連、自然言語処理など多岐にわたっていてその内容によっても色々変わってきます。いま紹介するのはこのタイタニックのコンペの場合の次のステップの案となっています。
よく行われるのが、EDA(探索的データ分析)と呼ばれるものです。これはざっくり言いますとデータセットを分析・調査してその特徴や傾向をまとめることです。これは改めていうほどでもないかもしれませんが、当然といえば当然の作業ではあるかと思います。そのデータセットがどういう特徴や傾向があるか、それを把握せずにモデルを作ったりしてもなかなか精度が上がらず沼にハマってしまいます。先ほど5行だけの出力をお見せしましたが、あれを見て色々と考えるのも規模の小さいEDAと言えますね。具体的には例えば各データ(つまりカラムごとに)の最大値や最小値、最頻値や平均値、分散などを算出して確認することがまず第一歩かもしれません。更にヒストグラムや箱ひげ図を使って可視化をしてより感覚的に把握することもとても重要ですしよく実施されます。
上記はあくまでカラムごと単独のEDAでしたが、変数間の傾向を把握することも大事です。よく使われるのが相関になります。細かく説明するのは省きますが2変数間の直線の度合いを示す値です。絶対値で1に近いほど直線の度合いが大きい、ということはより関係が深い、0に近いとお互いに影響を及ぼしにくいということを示す指標です。
なので、、単純に考えると、今回推定をする”Survived”と相関が0に近いものは、モデルに加えても邪魔になってしまう、相関が強いものを優先して入れた方がいいという洞察ができるわけですね。しかし相関が強い物同士を説明変数として入れてしまうと、多重共線性という問題も生じてしまいます。そのため”Survived”との関連だけではなく、その他の変数同士の相関を見ることも有用だったりします。以下が相関係数行列の出力例になります。
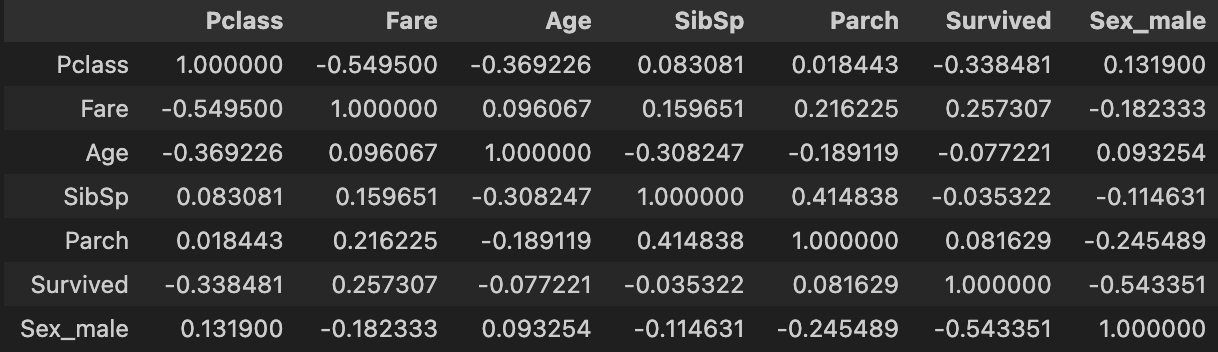
もちろん一概に相関ですべて説明はできないのですが、このようにしてデータセットの特徴を細かく捉えることがEDAの一つになります。
さらにこの後には、特徴量エンジニアリングというステップもよく実施されます。少し応用的な話なので、ここでは名前だけの紹介にとどめますが、「特徴量」と名前がついている通り、データセットに対して色々加工や処理を行うイメージです。なので、EDAのステップを経て行われるものでもあるかとは思います。
モデルを作って推定してみよう!
説明変数の選定
さて、本来なら細かいデータの構造を把握したり、特徴量エンジニアリングをするところなのですが、今回はブログでタイタニックコンペを簡単に紹介しようというのが趣旨なのでそこは今後深めていくという感じにして、実際にモデルを作って推定を行うというステップに進んでいきたいと思います。
”Survived”を説明する変数として、試しに”Pclass”、”Fare”、”Age”の3つを使ってやってみましょう。”Pclass”チケットのクラスになっているそうで、1=上層クラス(お金持ち)~3=下層クラス(貧乏)という感じです、”Fare”は運賃になっていて、当然ですが”Pclass”に対応しています。実際にデータをみると”Pclass”が1の人の運賃と、”Pclass”が3の人の運賃では10倍以上違いがあったりします。”Age”はもちろん年齢です。私は下層クラスのもう二つくらい下のクラスの人間なので、そもそもクルーザーや豪華客船のようなものに乗ったことはないのですが、タイタニックの映画やなんとなくのイメージで、上層クラスの人ほど船の上の方で、下層クラスの人ほど下にいるのかなと思っています。そして海難事故が発生すると、上の方の人が助かる確率が色々な条件から高いように感じております。実際にタイタニックの映画でも氷山に激突して大混乱になった際に下の人が上の階に上がるのを船員などが制限するようなシーンもあったような覚えがあります。なんかシャッターみたいなのを閉めるシーンとか、それをレオナルド・ディカプリオが破壊して突破するシーンみたいなのもあったような気がします。(思い違いでしたらすみません。。)もちろん命の価値は平等ではありますが、そういった傾向を考慮して変数を選んでみました。
ちなみに、先ほどの相関係数行列を見るとわかりますが、
”Survived”と”Pclass”の相関係数は-0.33
”Survived”と”Fare”の相関係数は+0.25
”Survived”と”Age”の相関係数は-0.07
となっていましたね。
”Survived”と”Pclass”には負の相関がある、ということですが、
”Survived”が0=死亡、1=生存であり、”Pclass”が1=上層クラス(お金持ち)~3=下層クラス(貧乏)ということからも、クラスの数値が上がると、”Survived”が0つまり死亡になる傾向が少しある、ということでなんとなく当てはまっていそうな雰囲気はあります。”Fare”が正の相関があるということはつまり・・・ここは皆さんもイメージしてみてください。年齢はあまり相関がないみたいですね。よく、子供を優先して助けるみたいなのがあったので、そこに相関があるかと思ったのですが、相関係数だけではそこは見えませんでした。
最強のモデル!?
さて、こうして使う変数を絞ったところで、次はモデルを選んでいきたいと思います。モデルは星の数ほど存在しています。例えば過去の私のブログで紹介した、線形回帰モデルもモデルですし、時系列分析の1次の自己回帰モデルもモデルです。このモデルの選択で推定結果は大きく変わってきます。今回は0=死亡 or 1=生存の推定をする、いわゆる分類問題で、分類数が2つなので、二値分類問題となります。そのため数値を推定する線形回帰モデルは使えませんし、時系列データでもないので1次の自己回帰モデルも使えません。一番基本的な分類問題を解くモデルとすると、ロジスティック回帰モデルというのがあります。それを使ってみてもいいですが、今回はこういった分類問題を行う際のある種の王道のモデルでもあるLightGBMというのを使ってみたいと思います。細かい説明は省きますが、ニューラルネットワークを使わないモデルとして絶対的な地位に位置するモデルです。かなりの精度が期待できます。データサイエンティストの中では「初手はまずLightGBM」みたいな雰囲気があったりします。
では実際にそのLightGBMを使い、”Pclass”、”Fare”、”Age”の説明変数で、”Survived”を推定してみます。LightGBMのパラメータは一旦このような感じにしてみました。

これをもとに学習してみます。
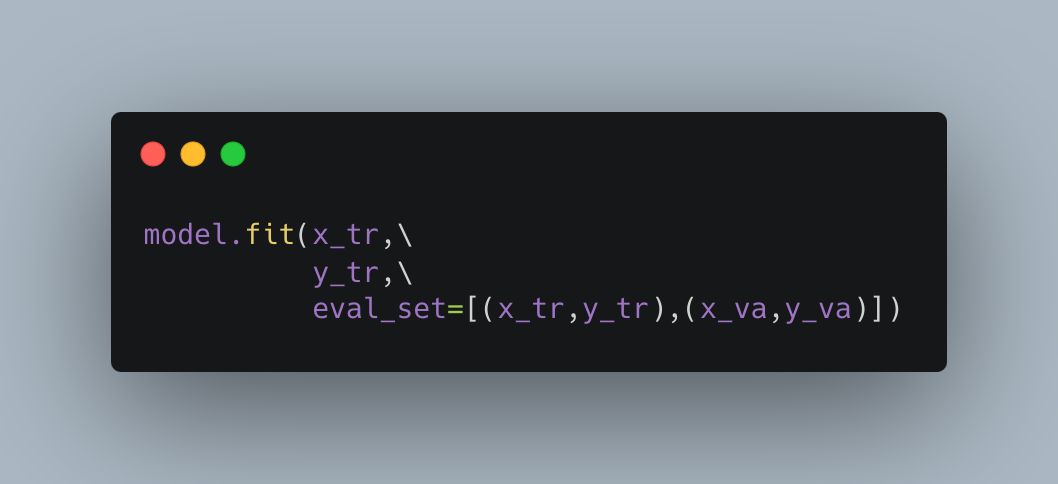
細かい説明は省きますが、paramsでパラメータを設定して、fitで学習しています。
そして学習したモデルで、検証データを使い、精度の検証をしてみましょう。
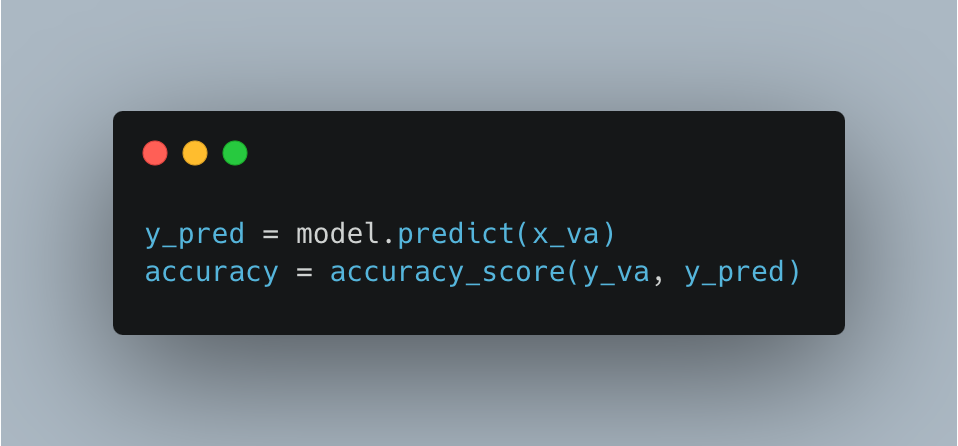
得られたaccuracyは・・・約66%でした。つまり0=死亡 or 1=生存という推定の正解率が約66%だったということです。まあ一旦やってみたというところなので、ぼちぼちというところかと思います。こうやって最初に作ったものをベースラインと言ったりします。名前の雰囲気の通り、これをベースとして色々と試行錯誤をして精度をどんどんあげていくわけですね。ここまでできれば、一旦コンペでの推定ができたということになります。なのでこのモデルでtestデータの418人分の生死を推定をしてkaggleへ提出することができます。実際に上のモデルで推定して提出してみたところ、ランキングは第12,778位でした。まだまだ先が長いことはお分かりになるかと思います。
ただ、これで無事に念も習得ができたと言っていいでしょう。ハンター裏試験も無事合格です。ちなみに、”Pclass”、”Fare”、”Age”に加えて、性別の”Sex”も説明変数にいれてモデルを作ったところ、その精度は約81%まで一気に上昇しました。81%だとそこそこ良さそうかなと思いきや、kaggleランキングの上位はaccuracyが100%という数字がずらりと並んでいます。418人の生存を100%正解している人がゴロゴロいるわけですね。漫画の後半でもそうでしたよね、あの圧倒的強さの戸愚呂弟がB級妖怪・・・霊界にはA級やら、それ以上のそもそも強さを測ることができないやばい強さのS級妖怪がうようよしている状況でした。おっと、これは『ハンター×ハンター』ではなく、『幽遊白書』ですね。冨樫先生違いでした。(2024年10月7日より1年9ヶ月ぶりの連載再開〜!クラピカどうなる!?)
終わりに・・・
Kaggle以外にも色々!皆さんも挑戦してみよう!
こうして、精度は低いもののKaggleの登竜門であるタイタニックコンペに参加して分析結果を提出することができました。Kaggle以外にもデータコンペは存在していまして、例えばSIGNATEやNISHIKAというのも有名です。私も過去に参加したことがあります。最初にお話はしましたが、コンペの種類は多岐に及んでいてタイタニックはあくまでチュートリアルなので簡単です。開催中のコンペを見て頂きたいと思いますが、内容やデータ構造はとても複雑で、まずベースラインを作るのにとても苦労したりします。ただ、とてもやりがいや楽しさもあり、技術や知見の向上がかなり期待できます。もちろんKaggleのランクが高いから実務で活躍できるのかなど一概には言えない部分はあるかもしれませんが、ワンチャン賞金ももらえるのでみなさんもぜひとも挑戦してみましょう!一日一万回、感謝のパラメータチューニング!
弊社ではデータ基盤の構築から分析や推定など、データに関してトータルでのご支援が可能です、興味を持っていただけましたらお問い合わせくださいませ!









