
光学文字認識(OCR: Optical Character Recognition)技術は、手書き文字や印刷された文字をデジタルテキストに変換するための強力なツールとして、さまざまな分野で活用されています。例えば、郵便物の自動処理や文書デジタル化、さらにはスマートフォンでのテキスト読み取りにも利用されています。その基盤となる技術の一つが、機械学習です。そして、手書き数字の識別に特化したMNISTデータセットは、OCRの学習において最もポピュラーなデータセットの一つとして広く知られています。
今回は、MNISTデータセットを用いた手書き文字認識の仕組みと、それを応用した最新のOCR技術で実現できる「PDF文書やレシートの自動読み取り」、「手書き文字や複雑なフォントの認識」、「画像からのテキスト抽出」などの機能について解説します。
ブログ作成者紹介
Vareal株式会社
名前:W.H
部署名:データサイエンス部
役職 (ポジション):データサイエンティスト
業務内容:生成AI(Chatbot)ソリューション開発、AI・データサイエンスを活用したビジネス課題の解決支援・提案など
得意なこと:書くこと (考察 & レポーティング)
趣味:読書、散歩、映画鑑賞
目次
- MNISTデータセットとは?
- MNISTを使った文字識別
- Kaggle「Digit Recognizer」コンペティション
- ランダムフォレストによる手書き数字認識
- 1. ライブラリのインポート
- 2. データセットの確認
- 3. 正規化 (前処理)
- 4. バリデーションの作成
- 5. モデル構築
- 6. ランダムフォレストとは?
- 7. モデルの評価
- 8. 予測
- 9. 提出ファイルの作成
- 10. まとめ
- OCR技術の最前線!
- 1. PDF文書やレシートの自動読み取り
- 2. 手書き文字や複雑なフォントの認識
- 3. 画像からのテキスト抽出
- 使い方のポイント!
- おわりに
MNISTデータセットとは?
MNIST(Modified National Institute of Standards and Technology)は、手書き数字の画像データセットで、機械学習の研究における定番のベンチマークとして使われています。このデータセットは、0から9までの数字を手書きした画像を集めたもので、28×28ピクセルのグレースケール画像として提供されています。

MNISTデータセットの構成
・訓練用データ: 60,000枚の手書き数字画像
・テスト用データ: 10,000枚の手書き数字画像
これらの画像を学習アルゴリズムに与えて訓練することで、手書き数字を正確に認識できるモデルを構築できます。
MNISTを使った文字識別
MNISTデータセットを使った手書き数字認識は、最も基本的な文字識別タスクの一つであり、機械学習や深層学習を学ぶ上での重要なステップです。この課題に取り組むことで、文字認識における基本的な技術を習得できます。
基本的なアプローチ
手書き数字認識の最も基本的なアプローチは、ニューラルネットワーク(特に多層パーセプトロン)を使用することです。ニューラルネットワークは、入力データ(手書きの数字画像)を層を重ねて処理し、特徴を学習して最終的に数字を予測します。さらに、近年では、畳み込みニューラルネットワーク(CNN) が手書き文字認識において高い精度を誇ります。CNNは画像内の特徴を自動的に抽出できる為、画像分類タスクでは非常に効果的です。
画像分類タスクには様々なアプローチがあります。今回はその中でも、kaggleの「Digit Recognizer」というコンペをテーマに、MNISTデータセットを使った手書き数字認識にランダムフォレストを使用するアプローチを紹介します。ランダムフォレストは決定木を複数組み合わせて分類を行う、シンプルで理解しやすく、機械学習の基礎を学ぶのに最適なアルゴリズムです。
Kaggle「Digit Recognizer」コンペティション
Kaggleの「Digit Recognizer」コンペティションは、MNISTデータセットを用いた手書き数字認識の実践的な演習として非常に有益です。このコンペティションでは、MNISTデータセットを使って手書き数字の分類モデルを作成し、その精度を競います。
Kaggle「Digit Recognizer」コンペティションの詳細はこちらで確認できます。
ランダムフォレストによる手書き数字認識
では、実際にMNISTの手書き画像のデータセットを用いて、数字を識別するランダムフォレストの機械学習モデル(数字認識装置)を構築してみましょう。
データセットの詳細
・データファイル(train.csv, test.csv)は、0から9までの数字を手書きしたグレースケール画像
・各画像は縦28×横28ピクセル (合計784ピクセル)
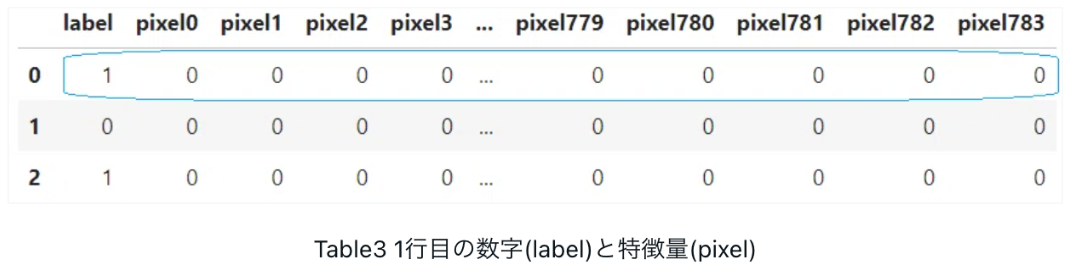
・手書き数字データ(train.csv)は785列
・最初の列は 「label (正解ラベル)」、残りの列は「該当する画像のピクセル値 (特徴量)」
1. ライブラリのインポート
今回使用するライブラリはこちらです。(まずは、インポートします。)

2. データセットの確認
インポートが終わったら、データセットの中身を開いて、どのような画像が入っているか可視化して確認してみます。
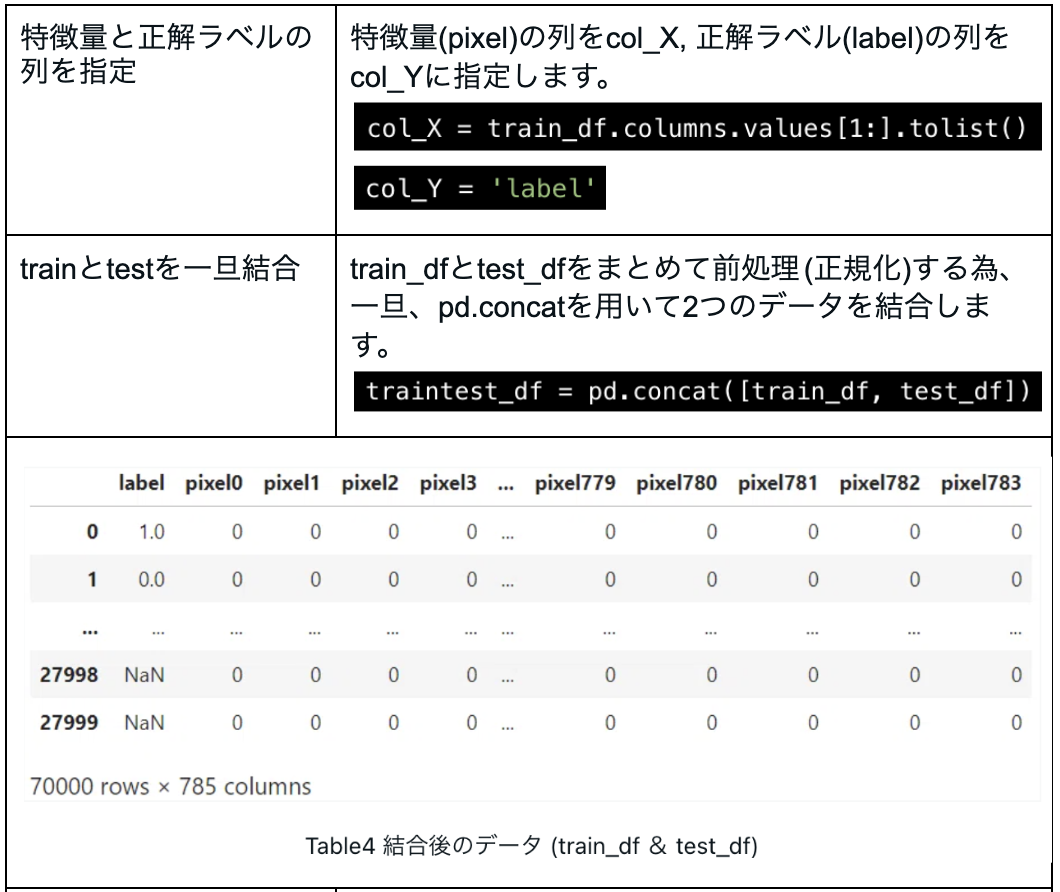
先ずは、pd.read_csv()でkaggleのinputからデータセットを読み込みます。今回は42,000行, 785列の「手書き数字データ (train_df)」と、28,000行, 784列の「テスト画像 (test_df)」があります。train_dfにだけある一番左の「label (0~9の数字)」が機械学習モデルで予測(識別)できる様にしたい項目です。
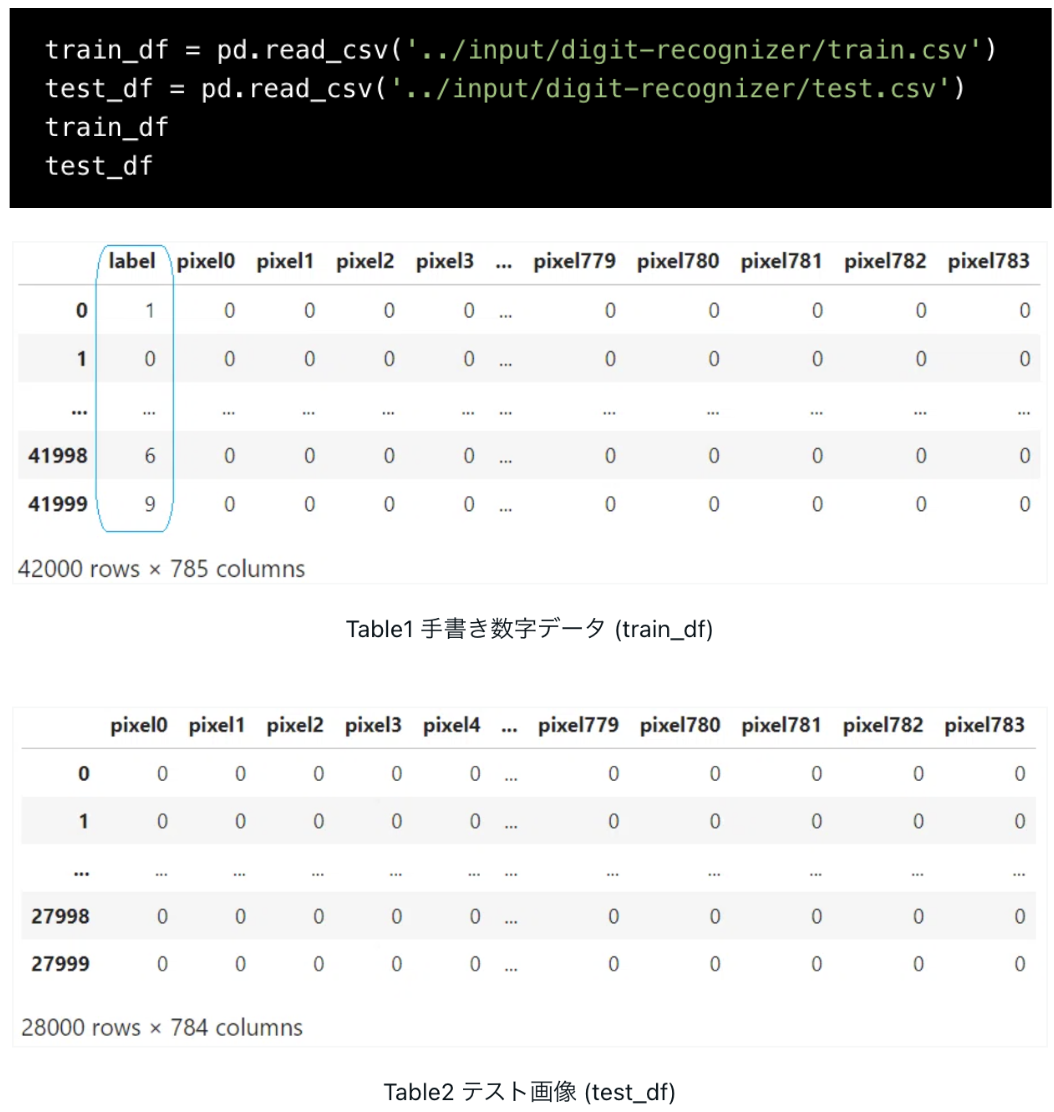
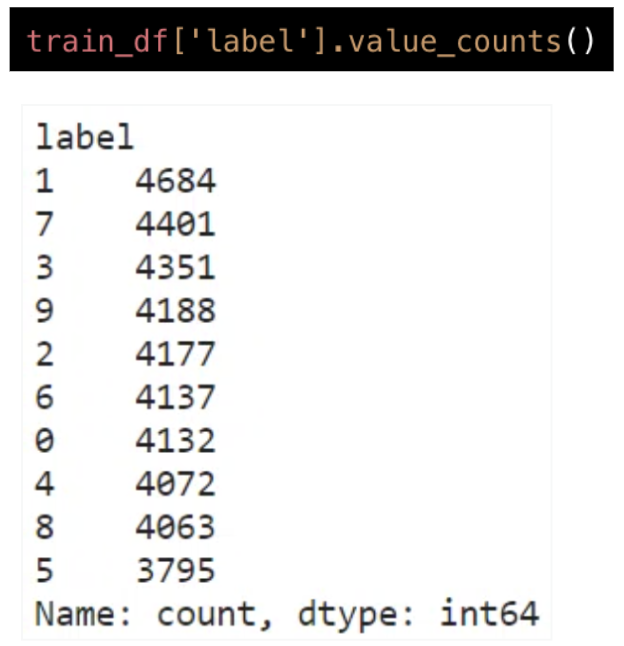
次に、.value_counts()でlabel列の各数字(0~9)の数を集計して、正解ラベル(0~9)の数を確認します。各数字の数は概ね3,800~4,700の範囲内で、大きな偏りはない様です。
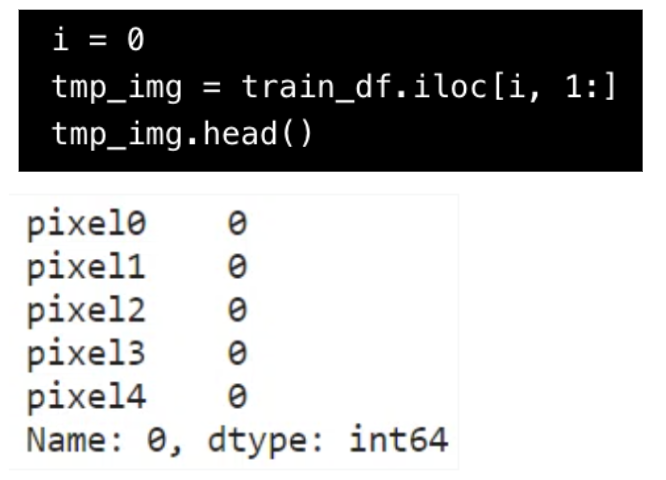
次に、手書き数字データ(train_df)内の「特徴量(pixel)」を元に、1行目(インデックス番号 i=0)のlabelである「1」の画像を表示してみます。
.ilocでtrain_dfから1行目(i=0) の特徴量(pixel)を抽出し、
.valuesで抽出した特徴量(tmp_img)を配列(numpy array)に変換します。
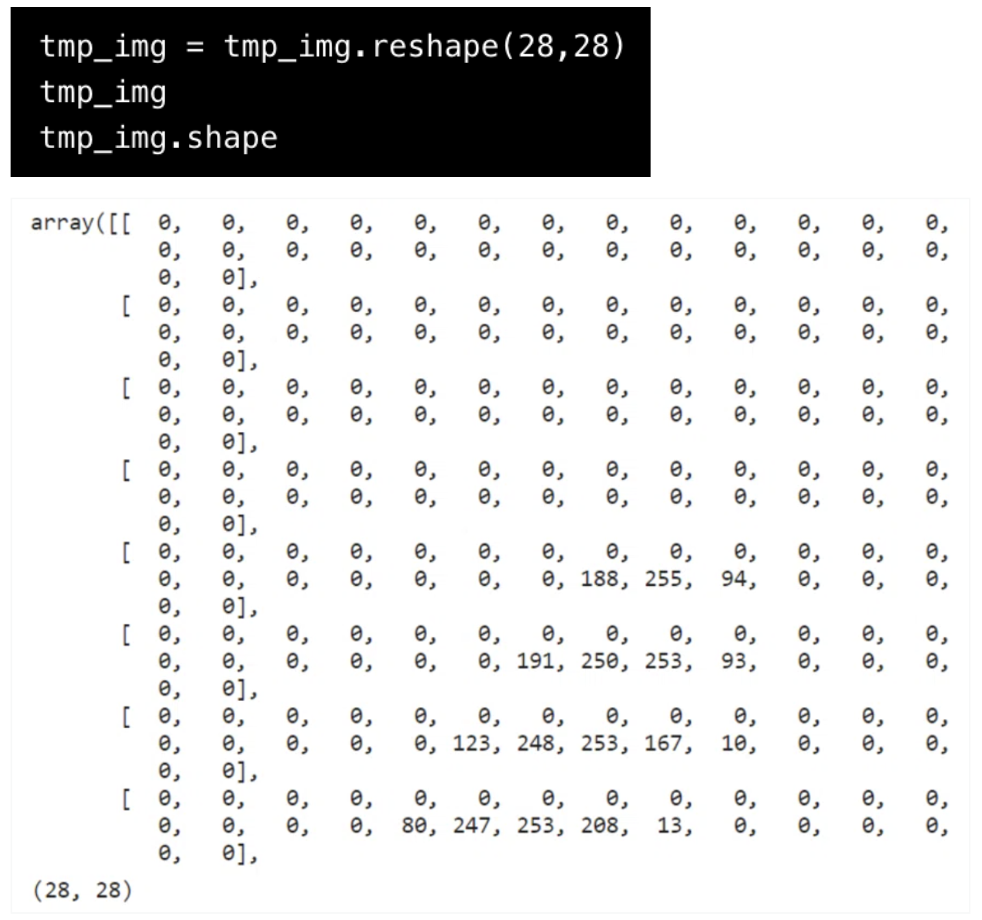
最後に、.reshapeで配列の形(shape)を784(列数)から「2次元画像(28×28)」に変換し、
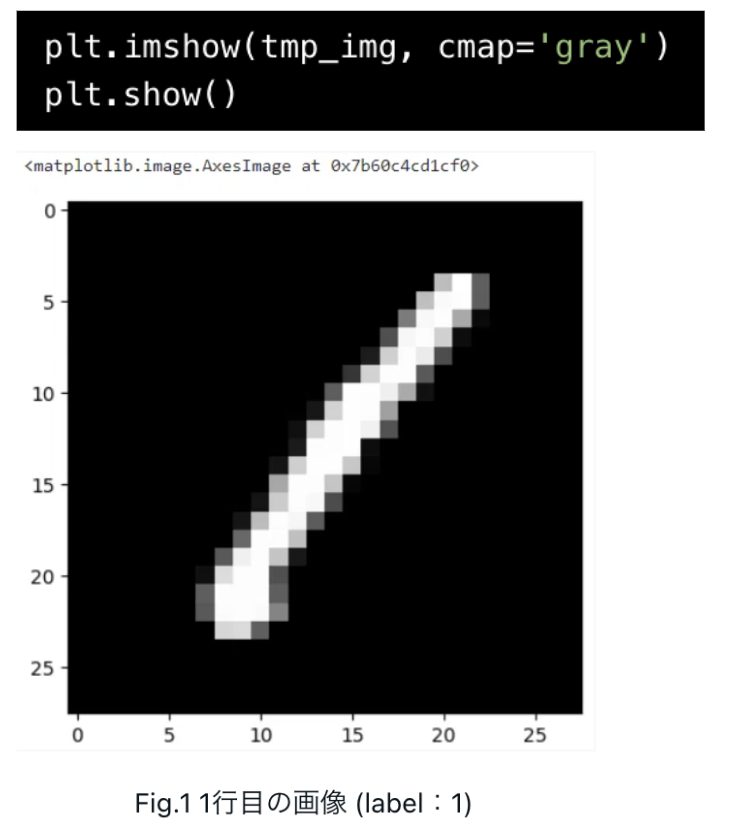
plt.imshowで配列(tmp_img)を画像として表示します。(1行目(i=0)のlabelである「1」の手書き数字が確認できました。)
3. 正規化 (前処理)
次に、以下の手順で、画像データのピクセル値(0~255)を0~1の範囲に揃える正規化 (前処理)を行います。これにより、モデル性能の向上や、学習の高速化などが期待できます。

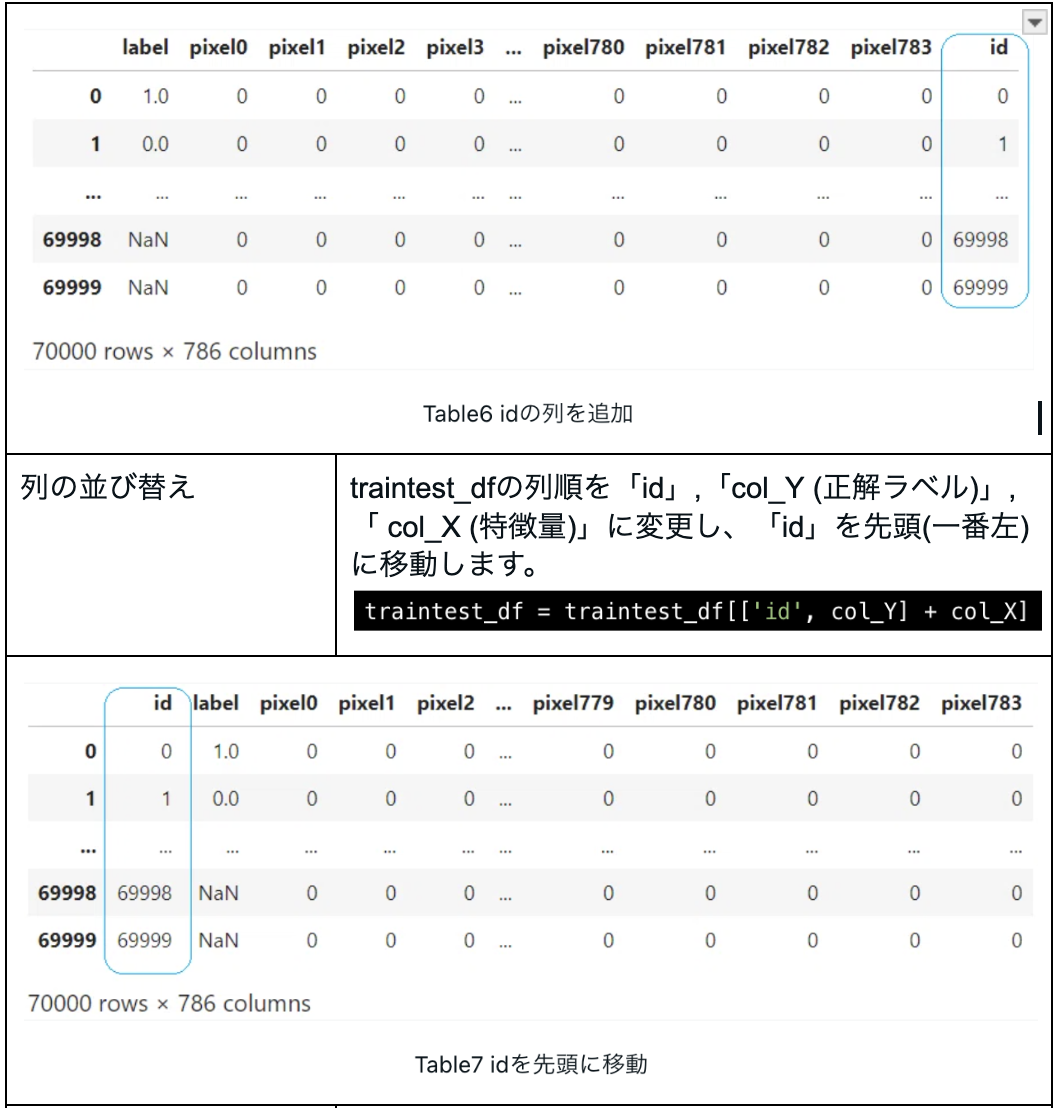

4. バリデーションの作成
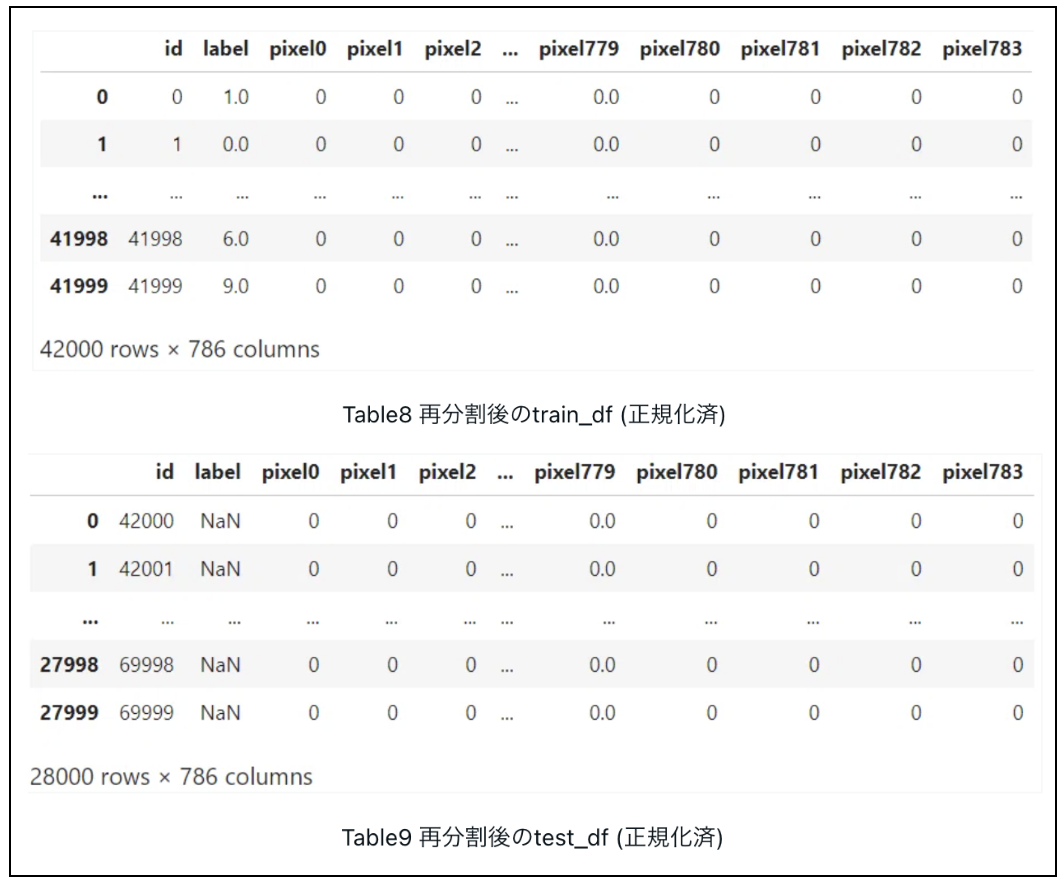
次に、交差検証を行う為、以下の手順で、前処理済のデータを訓練データ(x_train, y_train)と検証データ(x_valid, y_valid)に分割します。
(今回はhold-out法を複数回繰り返す「k-fold Cross Validation」を用います)


5. モデル構築
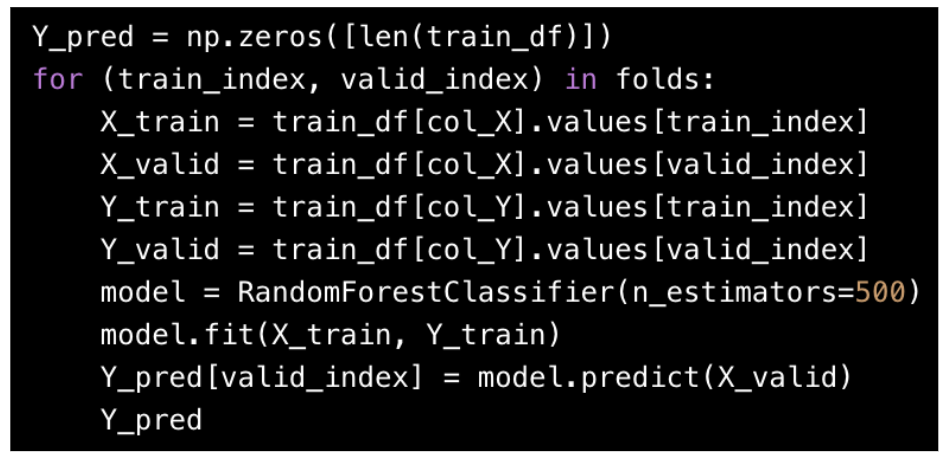
次に、for文を用いて、各fold毎に以下の処理(モデル学習&予測)を繰り返し、予測結果を「Y_pred」に代入します。
・特徴量(X_train, X_valid)と正解ラベル(Y_train, Y_valid)を指定
・分類のアルゴリズムを定義 (今回はランダムフォレスト)
・モデルの学習 「.fit (X_train, Y_train)」
・検証データでの予測値「.predict (X_valid)」を算出し、Y_predに代入
※ for文でループさせる前に、np.zerosで予測結果を入れる「train_dfの長さ(データ数)分の0行列の箱 (Y_pred)」を作成しておきます。

6. ランダムフォレストとは?
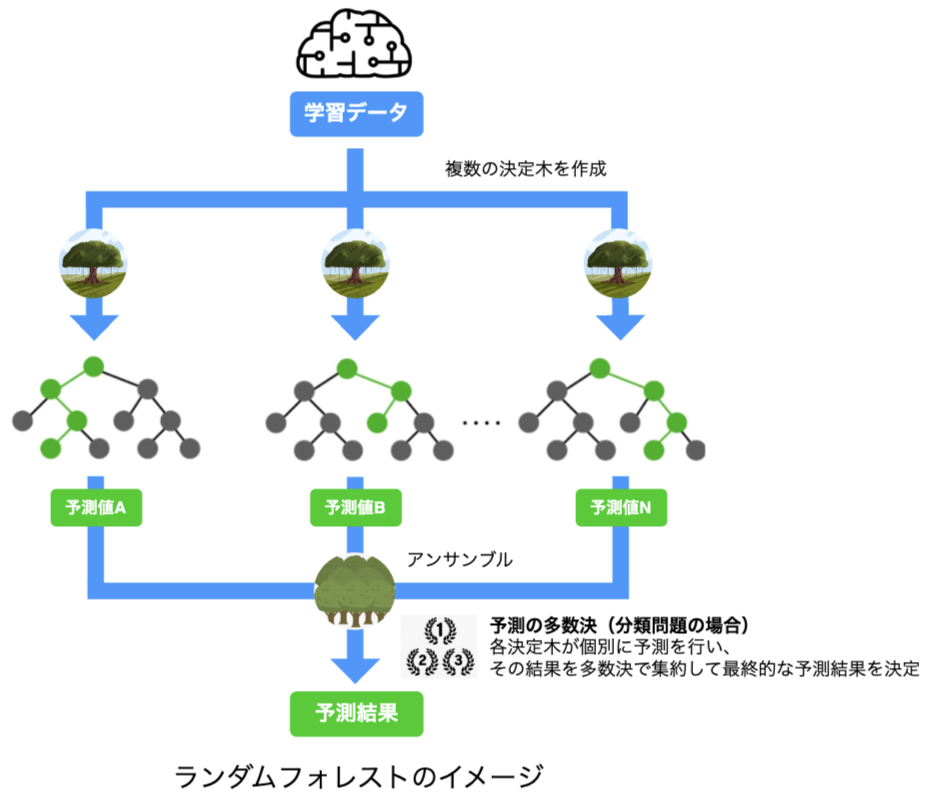
ちなみに、ランダムフォレストは機械学習のアンサンブル学習手法の一つで、複数の決定木を使って多数決を取ることで、高い精度の予測を行うことができます。ランダムフォレストは決定木の過学習を抑制し、一般的に単一の決定木よりも高い予測力を持ちます。
実際にランダムフォレストを使う際には、決定木の数や深さ、データのランダムなサンプリング方法(ブートストラップサンプリング)などのハイパーパラメータの設定が重要です。これらのハイパーパラメータを適切に調整することで、モデルの性能を最大化することができます。
7. モデルの評価
次に、このランダムフォレストのアルゴリズムで学習したモデルの予測精度を正解率(acc)で評価します。この正解率(acc)は、「正解ラベル (train_df [col_Y] )」と「予測値 (Y_pred)」の数字が一致したかどうかの真偽値(True(1) or False(0))を集計し、その平均値をとる事で、算出できます。

8. 予測
交差検証(k-fold)での正解率(識別成功率)は 約97% (acc≒0.97)、3%外れていますがまずまずの予測精度です。次は、このモデルを使ってテストデータの「label (識別したい数字)」を予測します。
テストデータ(test_df)の特徴量を抽出して、
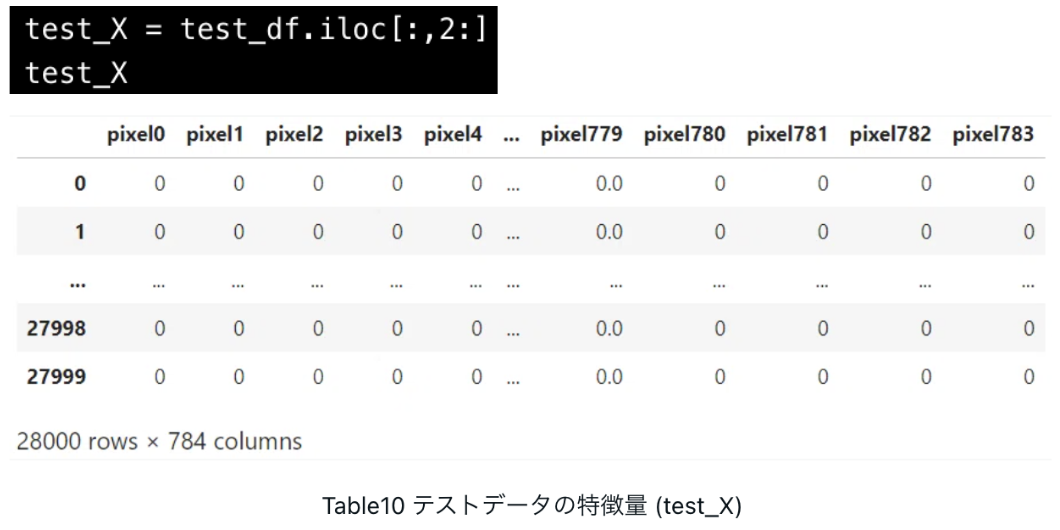
.predictにテストデータの特徴量(test_X)を入れて、「識別したい数字(label)」を予測します。
9. 提出ファイルの作成
最後に、予測結果(test_pred)を提出ファイルに入れて、submit(提出)します。
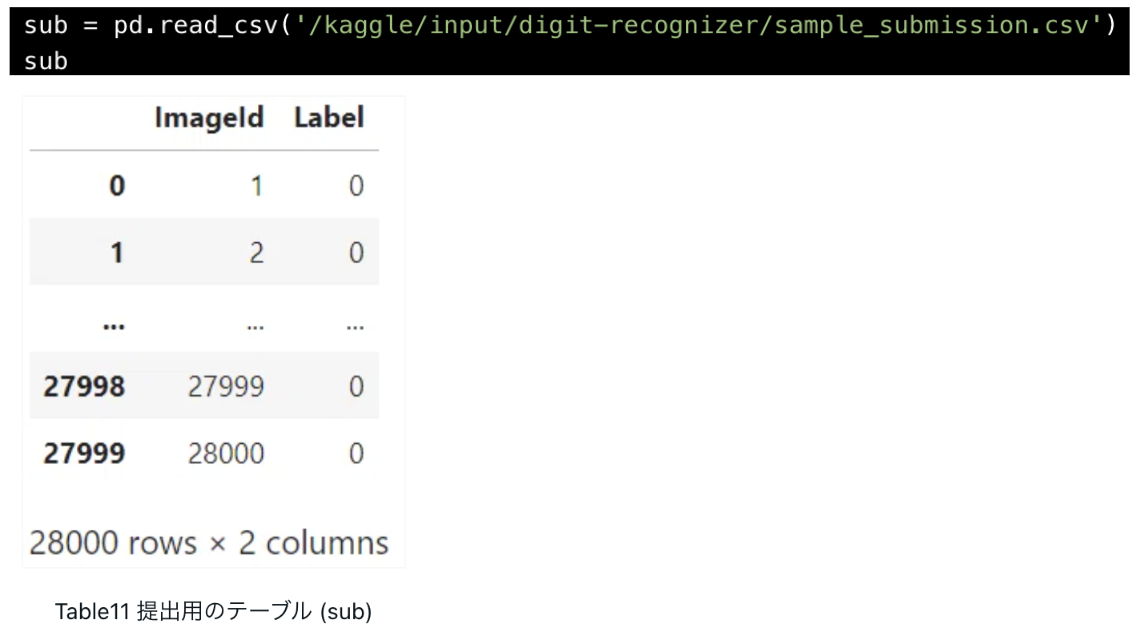
pd.read_csvで提出用のテーブル(sample_submission.csv)を読み込んで、
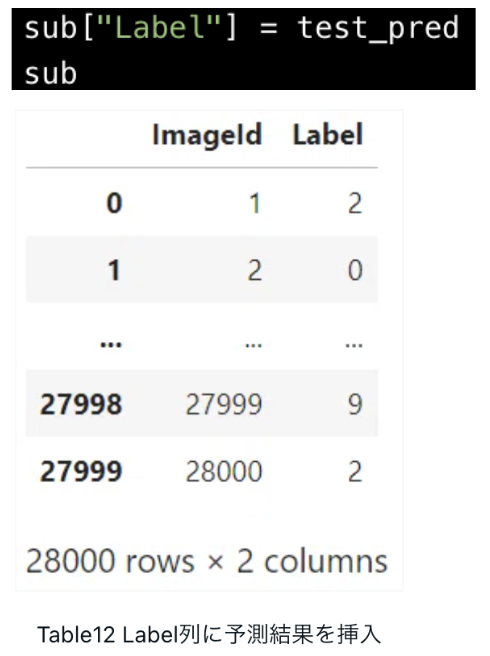
提出用のテーブル(sub)のLabel列に「予測結果(test_pred)」を挿入し、
.to_csvで作成した提出ファイル(sub)を保存します。この提出ファイルをkaggleのNotebookにSaveし、Submit(提出)すると、スコア(正解率)が表示されます。
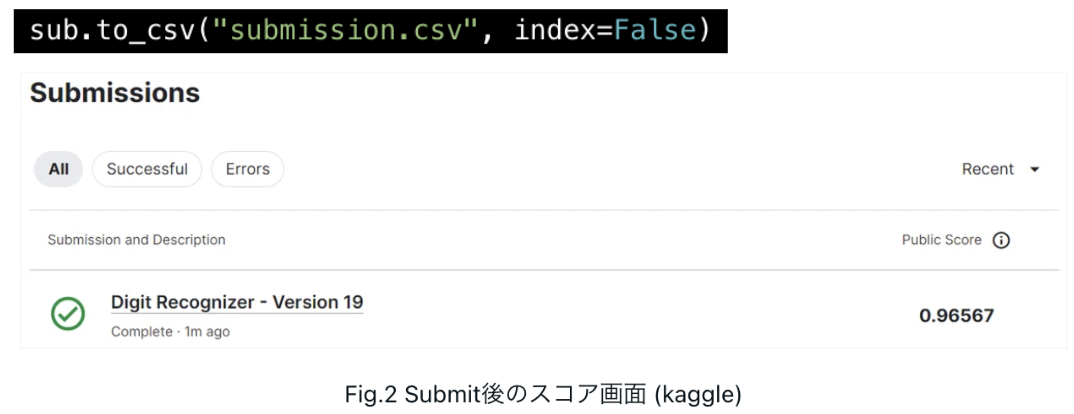
10. まとめ
といった具合に、画像を構成する各ピクセル値の配列(パターン)と正解ラベル(正解の数字)の関係性を大量に学習したモデルを構築する事で、未知の画像の数字(あるいは文字, 記号など)をそのピクセル値(0~255)の配列から予測できる様な仕組みになっています。
いかがでしたでしょうか。ここまでは、70,000枚の数字画像データ(MNIST)を用いて、正則化の前処理を行い、ランダムフォレストの学習モデル(手書き数字の識別装置)を構築する方法を紹介しました。では、文字識別の基本的な仕組みを理解した所で、ここからは光学文字認識(OCR: Optical Character Recognition)と呼ばれる最新の文字識別技術やOCRソリューションについて紹介します。
OCR技術の最前線!
OCR技術は、手書き文字や印刷文字をデジタルデータに変換する技術であり、近年急速に進化しています。MNISTのようなシンプルな数字識別から始まり、現在では手書き文字、印刷文字、さらには手書きの手紙や複雑なレイアウトが含まれる文書の認識へと進化しています。
1. PDF文書やレシートの自動読み取り
PDFや画像形式のレシートから文字を抽出することは、OCR技術の最も一般的な用途のひとつです。これには主に以下の2つのケースがあります。
スキャンした文書や画像内の文字認識
スキャンしたPDF(画像形式)やレシートの写真には、通常、文字が画像として保存されています。OCR技術を用いることで、これらの画像内の文字を識別し、テキストデータとして取り出すことができます。例えば、レシートの内容(商品名、価格、日付など)をデータベースに自動で入力することができます。
テキストベースのPDFからの抽出
テキストが埋め込まれたPDFファイルからは、OCRを使わずに直接テキストを抽出できることもありますが、PDFの構造によっては読み取りが難しい場合もあります。その場合、OCRを使って正確にテキストを取得します。
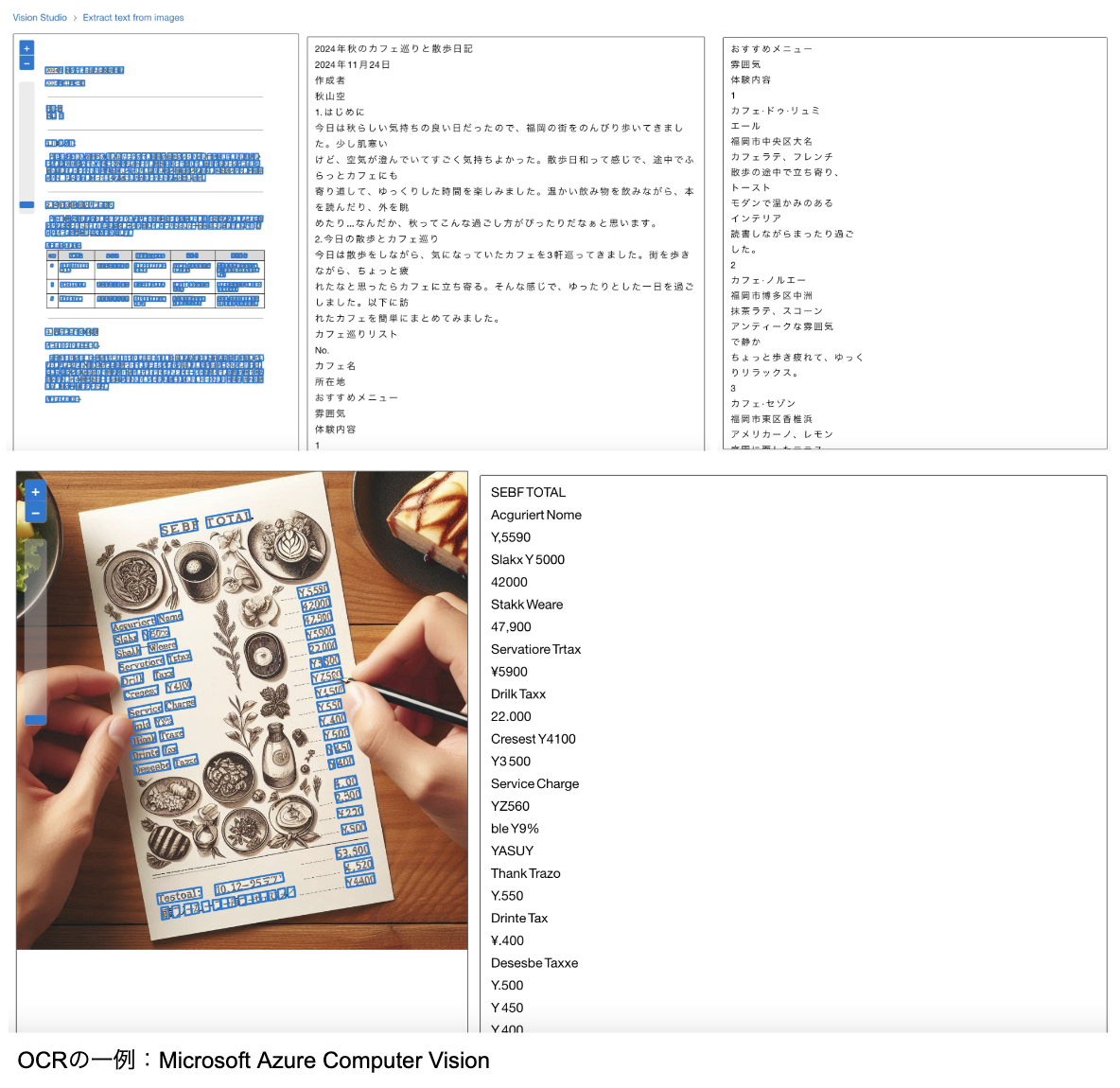
2. 手書き文字や複雑なフォントの認識
OCR技術は、手書き文字やフォントが複雑な場合にも有用ですが、その認識精度は、使用するOCRエンジンや前処理技術によって大きく変わります。
手書き文字の認識
手書き文字の認識は、活字の文字よりも難易度が高いです。手書きの文字は個人差が大きく、文字の形状や太さが一貫していないため、正確な認識には高度なアルゴリズムが求められます。最新のOCR技術では、機械学習(特に深層学習)を用いて手書き文字のパターンを学習し、認識精度を向上させています。
複雑なフォントの認識
OCRが難しいフォントには、装飾的なフォントや特殊なデザインが施されたフォントがあります。これらの文字は通常の印刷物よりも認識が困難です。しかし、OCR技術はフォント識別やパターン認識を行うため、トレーニングされたモデルによってある程度の認識が可能です。複雑なフォントにも対応するためには、大量のデータと十分な学習が必要です。

3. 画像からのテキスト抽出
OCRは、単にスキャンした文書やPDFだけでなく、任意の画像から文字を抽出する機能も提供します。これには以下のようなケースがあります。
写真からのテキスト認識
カメラで撮影した画像(例えば、街中の看板や書類の写真)から文字を認識することができます。これには画像の解像度、照明、歪みなどの影響が関係するため、前処理や画像補正が重要になります。
画像内のテキスト領域検出
OCR技術は、画像内で文字がどこに位置しているのかを検出することができます。これにより、文書の中でテキストを正確に認識し、抽出することが可能です。テキスト領域を特定する「領域検出」技術と、抽出されたテキストを認識する「文字認識」技術が組み合わさって、効果的なテキスト抽出を実現します。

使い方のポイント!
OCR技術を活用する最大のポイントは、面倒な手入力を省いて、データの取り込みを自動化できるところです。例えば、レシートや請求書をOCRで読み取ると、必要な情報(金額や日付など)を自動で抽出してくれるので、経理業務がスムーズに。さらに、手書きのメモや名刺をOCRでデジタル化すると、情報をすぐに検索できるようになり、管理も格段に楽になります。

おわりに
OCR技術を活用することで、手間のかかる作業がぐっと楽になり、業務の効率化が進みます。例えば、レシートや請求書を自動で読み取って必要な情報を抽出したり、手書きのメモや名刺をデジタル化して管理しやすくすることで、日々の業務がスムーズに進みます。今まで時間がかかっていた作業を省略し、もっと重要なことに集中できるようになるのが、OCRの大きな魅力です。
ぜひ、あなたもOCRを取り入れて、業務の効率化を実現してみてください。きっと、作業の負担が減り、仕事がもっと快適になりますよ!今回紹介したOCR技術以外にも、当社ではさまざまなAIソリューションを提供しています。自社に合わせた独自のAIツールを開発したい、既存サービスにAIを組み込みたい、導入方法について相談したいなどのご要望にお応えします。サンプルデータを使った技術検証(POC)も実施していますので、興味のある方はぜひお気軽にお問い合わせください。








