
身近になったどころか、もはや今の私たちの生活に欠かせなくなりつつあるAI。このブログではそんなAIと、AIに密接に関わる機械学習やその他の重要な用語に関して簡単に紹介をしたいと思います!
ブログ作成者紹介
Vareal株式会社
千田 康弘
部署名:データサイエンス部
役職(ポジション):データサイエンティスト
業務内容:データエンジニアリング 大規模言語モデルを使用したプロダクト研究開発支援
趣味:AmongUs(一緒にやる人募集中) ランニング
AIは機械学習??
AIってそもそもなに?
AIと聞いて皆さんは何を思い浮かべるでしょうか?身近な例でいえば、自動運転、お掃除ロボット、ペッパー君、SiriやAlexa、映画やアニメであればターミネーターやドラえもん、マトリックスなど色々と想像することができるかと思います。
しかし、AIの話になった際に皆さん一度は耳にしたことがあるであろう、「機械学習」や「ディープラーニング」というのは一旦どんなものなのか、イメージできない人も多くいらっしゃるのではないでしょうか?
「AIはディープラーニングなの?」
「AIは機械学習してるってこと?」
「深層学習っていうのも聞いたことがあるけど、あれ?じゃあニューラルネットワークってなに?」
かくいう私もデータサイエンティストとして業務をする前はよく理解できておらず、「これって同じ意味で別の言い方なだけなのかな?」などと思っておりました。
今回のブログではこういった用語を整理した上で、その技術を使ってどういったことができるのか紹介をしていきたいと思います!弊社ではAIを使ったレコメンドエンジン、異常検知技術開発、生成AIの活用など様々な実績がございます、興味を持って頂けましたらぜひご連絡くださいませ!⇨お問合せページ
AIの誕生と発展
AIにも種類がある?
今となってはすっかり市民権を得ているAIですが、その歴史は意外(?)と古く、1956年の米国のダートマス会議で人工知能研究者である『ジョン・マッカーシー』が人工知能(=Artificial Intelligence)という言葉を使用したところから始まったというのが有名なお話です。AIの定義は様々存在している印象がありますが、わかりやすい意味としては、「人間の脳に近い働きをするコンピュータープログラム」や、「人間の知的な行動を人工的に再現する事やそれを研究する分野」のようなイメージを持っておくとよいかと思います。
さて、ブログ冒頭で色々なAIに関連するキーワードを挙げさせて頂きましたが、列挙した単語の中では「AI」が一番大きな括りになります。その括りの中に関連する様々な用語が出てくるわけですね。
他で言い換える例として、野球を考えてみましょう。野球というのが大きな枠になり、その中にDeNAベイスターズや、大谷翔平選手などが出てくるという事です。さらに野球の上にはスポーツという括りがあるかと思いますが、そこはAIでは計算機科学となるのが一般的かと思われます。
大きな括りが分かったところで、AIの次に位置するカテゴリとしては、強いAIと弱いAIというジャンルがあります。野球でいうところの、現在の阪神タイガースと中日ドラゴンズに・・と分けるのはさすがに角が立ちそうなため野球の例はここでは控えましょう。
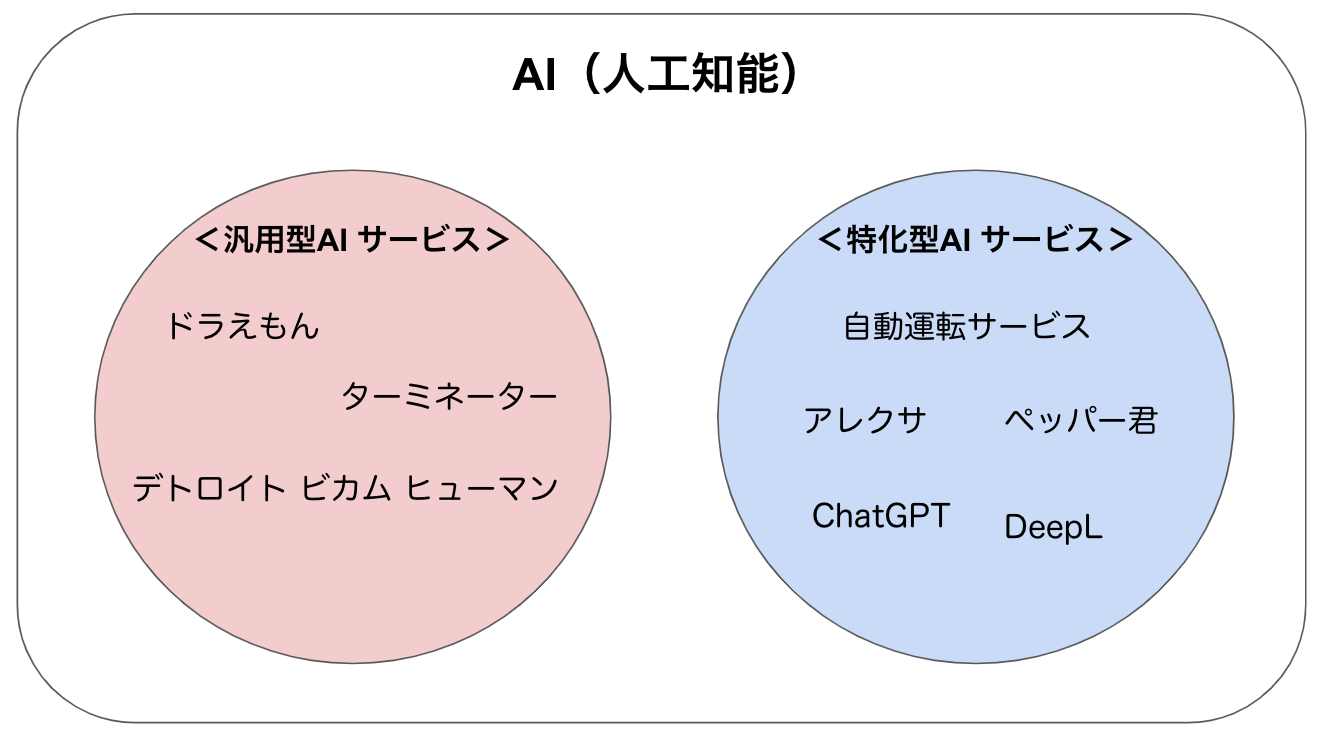
・・・と、冗談っぽく言ってみましたが、強い弱いは皆さまの想像する強者と弱者という意味とは若干異なります。別の言い方をしますと、汎用型AI(強いAI)と特化型AI(弱いAI)というものになります。
汎用型AIはまさにドラえもんになるでしょう。様々な出来事に対して自ら考え学習を行い判断し、そして問題を処理することができるそんなAIが汎用型AIです。いわば、AIの最終地点のようなイメージかもしれません。たくさんのAI技術が開発されていますが、未だ汎用型AIは開発されていないというのが一般的な認識です。
一方で、限定された領域の課題に特化して処理を行うことができるシステムが特化型AIとなります。つまり現在開発が行われ、活躍しているAIは全て特化型AIということでございます。
人間にも通ずる?機械学習とは・・・
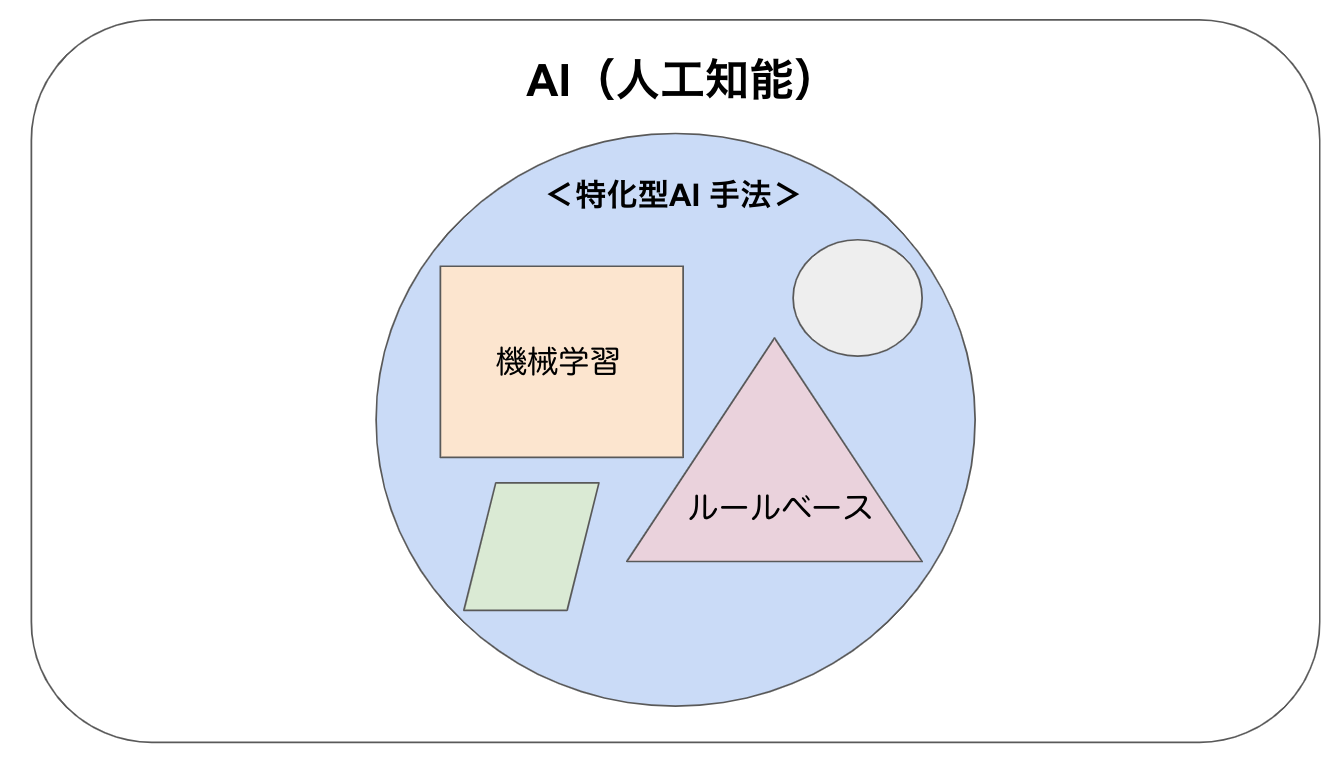
それでは、特化型AIの中はどうなっているのでしょうか?この内部に、重要なキーワードである機械学習があります。機械学習の定義も色々とある印象はありますが、コンピュータ科学者Tom Michael Mitchellは機械学習を
「コンピュータプログラムが、ある種のタスクTと評価尺度Pにおいて、経験Eから学習するとは、タスクTにおけるその性能をPによって評価した際に、経験Eによってそれが改善されている場合である。」とし、これが割と広い意味での機械学習の定義として用いられる傾向にあるかと思います。なにかややこしい定義な気もするかもしれませんが、考え方はとてもシンプルです。評価尺度として打率を考えてみましょう。タスクはバッティング、経験は素振りとすれば、素振りをしてバッティングというタスクを打率で評価した時に、素振りをすればするほど打率が改善される、この過程がコンピュータープログラムで成立することこそ、まさに機械学習ということになります。データコンペや実際の業務や機械学習を行なっているとわかりますが、正しく学習をしないと評価尺度が改善されなかったり、タスクが難し過ぎるとどう学習してもなかなか結果が出なかったりします。まさに人間の学習や成長の過程と同じなんですね。
余談ですが、機械学習の場合は『過学習』というAI開発をされていない方からするとあまり聞きなれない特殊な問題点もあります。これは文字通り勉強のし過ぎで、学習をし過ぎたが為に経験したことに特化してしまい、未知のデータで結果が出せないという現象です。
努力しても結果が出ないなんて事はよくある事ですが、野球で言えば試合で活躍できない原因として、バッティング練習は特定の球種だけ行なっていたり、ピッチング練習も同じスイングの打者だけになっていて、本番での未知の相手に対して対応できていないからという可能性もあるかもしれませんね。「過学習は人間にも存在するか?」ここはまた面白そうな研究テーマになりそうな気はしますが、話が大幅に逸れてしまいそうなのでここら辺にしておきたいと思います。もし皆さんのお子様がテストの点数が悪かった理由に過学習を持ち出してきた際は広い心で受け止めてあげましょう。
ということで、特化型AIの中に機械学習という方法論があることがわかりました。そうなると、「あれ?でも特化型AIの中に機械学習以外のものもあるの?」という疑問があるかと思いますが、それももちろん存在します。例とすると「ルールベース」というわれる方法論もありまして、細かい説明は省略させて頂きますが、要は特化型AIを作るための方法論が色々あるわけですね。その中で現在最も使用されているのが機械学習という方法で、野球でいうところの投手の中でもオーバースローの人もいればスリークォーターの人もいたり、バッティングも振り子打法とか一本足打法とか色々な方法があるのがまさにそれです。例がちょっと古いかもしれませんが、方法が色々あるというところを抑えておきましょう。
革新的モデル ニューラルネットワーク
若干野球の例が悪かったのではないかと追い込まれ気味ですが、最後にその機械学習という方法論のカテゴリの中に入ってくる、一番重要な概念のニューラルネットワークとディープニューラルネットワーク(=ディープラーニング、深層学習)について紹介したいと思います。先に話してしまいますが、ディープニューラルネットワークはニューラルネットワークの構造をより複雑にしたものというイメージですので、基本的にはこの後は統一して、ニューラルネットワーク(以降NN)で話を進めたいと思います。
ではそのNNとはなんなのか?というお話ですが、NNというのは数学的なモデルです。
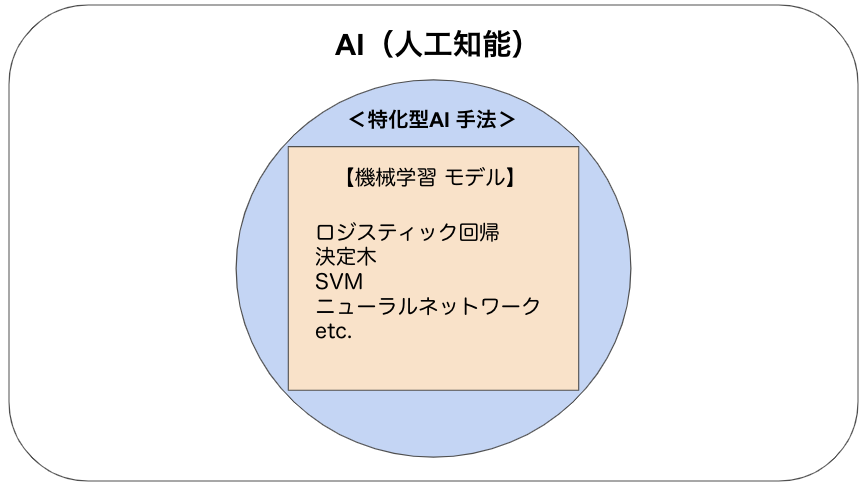
「じゃあ、モデルは他にも色々あるの?」と思われるかもしれませんが、それもその通りでございまして他にも様々なモデルが存在しています。
有名なところでいくと、回帰分析やロジスティック回帰、決定木やサポートベクターマシン(SVM)などがそれになります。機械学習を勉強すると絶対に出てくるモデル達です。これらのモデルの細かい説明も省略させて頂きますが、これらはそれぞれ機械学習の方法を使用したモデルということですね。スリークォーターという投法(方法論)があり、ダルビッシュ選手とか田中マー君とか佐々木朗希選手など色々な選手(モデル)がいると、そういうわけですね。
ちなみに余計な補足ですが、例えば回帰分析となると機械学習という方法を使わなくても使用することができます。回帰分析を勉強した方はむしろ最小二乗法や最尤法などで解く方法を勉強した人の方が多いはずで、「あれ?なんでAIで回帰分析?」と違和感を持つ方もいらっしゃるかもしれません。この点に関して細かく説明をする事は省略させて頂きますが、モデルに対してそれを最適化する方法が色々あるよ!くらいで考えておきましょう。ちなみに、機械学習は先程説明したような方法論であるのに対して、例えば最小二乗法などは連立方程式で解く方法です。そしてモデルは同じでも手法が違うだけで解の解釈も変わってきます。が、またその辺りの話は別の機会でお話をさせて頂ければと思います。
さて、このようにモデルはたくさんありますが、NNが革命的なモデルであり現在のAIの技術というと大半はNNが使われているという状況にあるかと思います。今回はあくまで概念の整理でありNNの細かい説明は省きますが、NNは人間の脳の構造を模した数理モデルでございまして、その他のモデル達と違って、大量なパラメータを持たせ複雑な表現を行うことが可能で、色々な構造のデータも応用ができ、データを特徴から自動で抽出してくれます。簡単な例は後ほどお見せするとして、こういった特徴からNNはとても革新的な方法だったのですね。
監督は誰?
ただ、NNはあくまでモデルの一つでありNNが最強ということではなく、状況によってはNNを使わないモデルの方が良い結果が出るケースも存在はしています。またNNでは多くのデータが必要で学習にも時間がかかり他のモデルと比べて学習のコストはかなり高いという欠点もあります。野球選手でいえば、NNは現在の代表的なピッチャーという事を考えると佐々木朗希選手などが挙げられるかもしれませんが、その他の選手に色々な特徴があり、その日のコンディションや打者やその他様々な状況によって抑えられるかなどは大きく変わってくるかと思います。
このようにどういったモデルを使用するかを考えるのは、データサイエンティストの腕の見せ所になってくるわけです。ということは、私のようなデータサイエンティストは野球でいうところの監督といってもいいかもしれませんね。
アヤメ(iris)の分類問題
実践例の紹介
それでは最後に迷監督である私の采配を紹介したいと思います。今回は機械学習を行う際に必ずと言っていいほど使用されるアヤメ(iris)という植物の分類問題を行なってみたいと思います

引用元: https://morioh.com/p/eafb28ccf4e3
setosa、versicolor、virginicaの3種類の分類問題を解くデータセットになっておりまして、特徴量としてがく片(sepal)の長さと幅、花弁(petal)の長さと幅の4つ、目的変数としてどの種類(0、1、2)かという内容になっています。scikit-learnというライブラリを使用することで簡単にそのデータセットをロードすることができます。
データセットはこのような感じです。
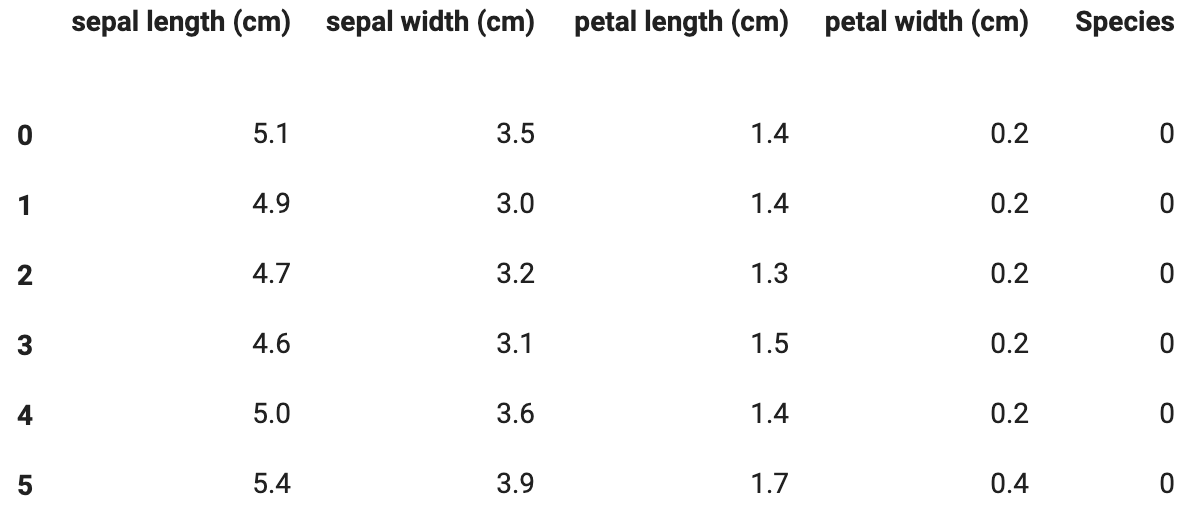
これは上から6個だけ表示しておりますが、データセットは1種につき50個×3種で合計150データ存在しております。
これらのデータで、分類問題をNNを使って実践をしたいと思います。
次のような設計にしてみます。
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(30, activation = tf.nn.relu, input_shape=(4,),kernel_initializer=he_normal()))
model.add(tf.keras.layers.Dense(50,activation = tf.nn.relu))
model.add(tf.keras.layers.Dense(70,activation = tf.nn.relu))
model.add(tf.keras.layers.Dense(3, activation = tf.nn.softmax))Model: “sequential” _________________________________________________________________
Layer (type) Output Shape Param # =================================================================
dense (Dense) (None, 30) 150
dense_1 (Dense) (None, 50) 1550
dense_2 (Dense) (None, 70) 3570
dense_3 (Dense) (None, 3) 213 =================================================================
Total params: 5483 (21.42 KB)
Trainable params: 5483 (21.42 KB)
Non-trainable params: 0 (0.00 Byte) _________________________________________________________________
細かい説明は省略致しますが、ノードの数は30⇨50⇨70⇨3としており、活性化関数はReluを、初期値としてHe初期値というのを指定しております。
その結果・・・
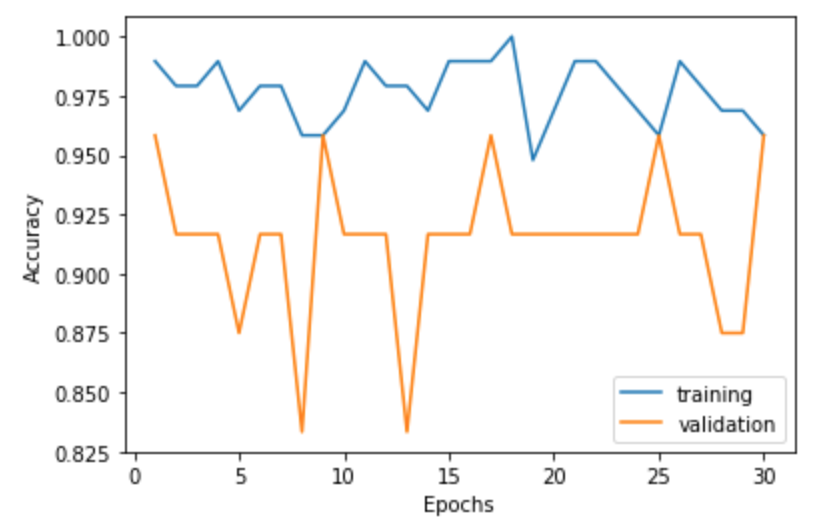
のようになりました。左の軸はAccuracyとなっておりこれはいわゆる正解率でこのモデルがどれだけ正しく3種類のアヤメを分類できているかを示しています。下はEpochsは学習の回数と簡単に考えてもらえば大丈夫です。30回の学習でおよそ95%の精度になっていることがわかりますね!ちなみに2色の折れ線グラフがありますが、青線がトレーニングデータ、オレンジ線がテストデータでございまして、そこらへんの説明は省略させて頂きますが、一旦ここではシンプルにこのモデルは95%くらいの精度なんだなぁと思って頂ければと思います。
まずまずの精度かとは思いますが、これは入門用のお手軽トレーニングセットですので、ある程度学習が上手くいようになっているかと思われます。現実のデータ(アヤメも現実のデータですが)が相手となるとまずデータの収集から始まり、データの前処理や加工、モデルの選定、学習、チューニングなどなど監督として行わないといけないことがたくさん存在しています。
ちなみにですが、全く同じデータを使用してNNではなく、決定木という有名なモデルを使用して問題を解いてみましたが、
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(max_depth = 4)
model.fit(X_train, y_train)こちらのモデルで行なったところ、テストデータ(先程の折れ線グラフでいうオレンジ線)の精度がなんと100%となりました。
今回のようなデータでは、NNを使用するよりも決定木を使用した方が精度が良いみたいですね。・・・ちなみに、NNモデルを更に応用することでアヤメの画像自体を入力として、分類問題も解くことができます。これはCNNと言われるモデルを応用したいわゆる画像分類というもので、まさにNNの実力が大きく発揮される場面の一つです。画像分類などの紹介はまたどこかで紹介させて頂ければと思います。
はい、ということで試合終了のお時間が来てしまいました。
今回は用語や概念の説明と簡単な例の紹介で、細かい手法や実務例などの省略させて頂きましたが、弊社ではAIによる推定・レコメンドエンジン、画像検知や画像分類、大規模言語モデルの応用などなど様々なサービスの開発を行なっておりますので、AIの活用をお考えの企業様、ぜひお問合せくださいませ!⇨案件のお問合せ
また、こういった開発をやってみたいという採用希望の方も募集してます、名将達の新たな挑戦をお待ちしております!
採用ページ
弊社公式Twitter(X)
弊社オリジナルキャラクターバレアルマンTwitter(X)









