
昨年のChatGPTの登場を皮切りに、多くの大規模言語モデル(LLM)の開発やそれに関わるライブラリ、アプリケーションのリリースが近年盛んになっています。このブログでは大規模言語モデルとその活用方法について紹介をしたいと思います。
ブログ作成者紹介
Vareal株式会社
千田 康弘
部署名:データサイエンス部
役職(ポジション):データサイエンティスト
業務内容:データエンジニアリング 大規模言語モデルを使用したプロダクト研究開発支援
趣味:Among Us ランニング
ChatGPTの登場
生成系AIの可能性
2022年11月のChatGPT登場以降、働き方が大きく変わった人も少なくないのではないでしょうか。契約書のレビュー、文章の要約、専用チャットボット、プログラミングコードの生成など、様々なタスクに対して非常に高い精度の回答を生成してくれるいわゆる大規模言語モデルの誕生により、自分の仕事もいずれはAIに奪われてしまうのではないかと不安に襲われたのは筆者だけではないかと思います。
ChatGPT出現以前は「生成系AI」といえば、画像に関わるAIを指している印象がありました。まるで人間が書いたようなイラストをAIが短時間で書き上げるサービスが多く展開され、学習に使われたデータや出力されたデータに関する著作権はどうなのか?法整備が間に合っておらず多くの議論が行われていたはずですが、それが霞んでしまうほど新たな「生成系AI」であるChatGPTの登場はインパクトがあったかと思われます。
異次元の学習
大規模言語モデルでよく注目される要素としては、その圧倒的なパラメータ数にあります。数千億という途方もない桁数で、学習するコストだけで数十億かかるとも言われております。従来のAI開発においては過学習とよばれる、モデルを複雑にしすぎた故に学習データに最適化されてしまい汎化性能が落ちるという、機械学習エンジニアの悩みの種がありました。しかしこのスケール感であれば、もはや全てのケースを学習しており過学習という概念自体ないのかもしれません。(ちなみにChatGPTの学習の際に過学習の対策をしているかChatGPTに質問したところ適切に行なっておりますと答えが返ってきました)
このブログを書いている現在も大規模言語モデルの開発や、それに関するライブラリ・アプリ開発の情報が絶え間なく更新されています。AIの法整備や倫理的な問題など課題は多くありますが、そこから得られる恩恵の方が遥かに多いことは確かでしょう。今まで人間では考えられなかったアプローチによる「知の創造」により、私たちの生活が更に「豊か」になっていくことが今後も期待されます。
〜VAREAL株式会社 企業理念〜

※弊社の会社概要等はこちらをご覧ください!
⇨会社概要
今回のブログでは、大規模言語モデルの活用方法の紹介を主に行なっていきたいと思います。弊社では大規模言語モデルを使用したサービスの開発も行なっておりますので、興味を持って頂けましたらぜひお問合せくださいませ!⇨お問合せページ
プロンプトエンジニアリング
新たなエンジニアの形
ChatGPTが登場して非常によく耳にする用語として、プロンプトエンジニアリングというものがあるかと思います。それまで大変お恥ずかしいことながら、データサイエンティストの私はあまり聞いたことのない用語でした。プロンプトエンジニアリングの定義は色々とありますが、直感的に分かりやすい意味としては
「AI(人工知能)から望ましい出力を得るために、指示や命令を設計、最適化するスキルのこと」
NRI用語解説 https://www.nri.com/jp/knowledge/glossary
と理解をしておき話を進めていきたいと思います。
なぜ大規模言語モデルを使用する上でプロンプトエンジニアリングが重要なのか?という疑問があるかと思いますが、それは大規模言語モデルのテキストの入出力の処理の構造が深く関係しています。(細かい説明は多くの解説記事が出回っているためそちらを参照して頂くとします)
そもそもAIって?
ChatGPTを使ってチャットでやりとりをしていると、まるでChatGPT先生が多くの物事を頭で理解していてそれを適切に答えているようにみえますが、実際にはChatGPTがチャットの質問を理解をして回答を生成しているわけではありません。人工知能というと、よくSF系の漫画などでみる、怪しげな水溶液の入ったどでかいケースにコードに繋がれた脳みそが入っていて・・・というようなものをイメージする方もいるかもしれませんが、AIは人工的に作られた脳みそで思考をしているわけではなく、あくまで確率的に出力の正しい可能性が高いものを回答として出力しているような処理になっています。AIでよく「学習」という言葉が使われるため、余計にそう思ってしまう部分があるかもしれませんが、学習というのはパラメータを最適化するための「反復計算」というイメージで、内容を記憶したり、理解しているということではないという事なんですね。
そのため、残念ながらChatGPTは国民的に人気アニメのドラえもんのようなAIということではないという事になります。・・・ではない、と言い切る事はできませんが、もしドラえもんがドラえもん自身が思考をしているわけではなく、あくまでのび太君のお願いの音声データをテキストに変換してそれを適切なトークンで処理して、のび太君に最も役立つ可能性が高い道具を確率的に計算して出力として選択しているとなるとちょっと寂しく感じてしまいますよね。あくまでドラえもんはより未来の汎用的なAIで人間と同じような感情を持っていて、機械的な処理ではなく、のび太君のためになる道具をドラえもん自身が考えて出しているとドラえもんをみて育った私は思うようにしたいと思っております。
若干話がそれてしまいましたが、そのような確率的な処理が背後にあるために、適切に質問(入力)を行わないと回答が安定しなかったり、全く期待しない回答が生成されたりしてしまいます。ただそれは、人間同士のコミュニケーションでも結局のところ同じなのではないか?と思う部分もありますが、人間の対話のプロンプト設計は大規模言語モデルよりかなり複雑になることが予想されますので、ここではこれ以上広げない事にしたいと思います。
プロンプトの設計とは?
それでは話を本筋に戻して簡単なプロンプト設計をしてみましょう。
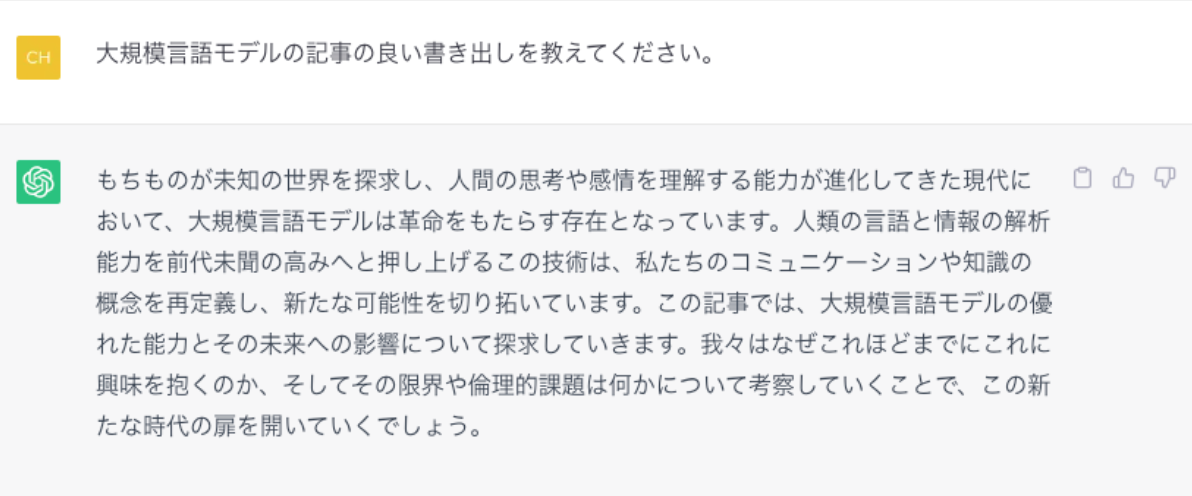
これは単純な例です。これ自体は個人的に書き出しとしては割とちゃんとしてそうかなとは思います。冒頭の「もちもの」とはなんなのか、ちょっとわかりませんでしたが。
では次のようにプロンプトを変えてみたいと思います。



かなり特徴的でよりそれっぽい書き出しが生成できたような気がします。
「魔法」という言葉がよく見られるのは気になりますが、兎にも角にもこのようにプロンプトを適切に設計する=プロンプトエンジニアリングによって、望ましくより適切な回答を生成することができ、これが今非常に重要なスキルとなっているということがわかるかと思います。
LangChain
より広がる可能性
さて、このようにプロンプト次第で無限の可能性を産んでくれそうな大規模言語モデルではありますが、これをより簡単に制御をしたり、機能を拡張したり、アプリケーション開発をすることができるライブラリというのも公開されています。ここではその中の一つのLangChainを紹介したいと思います。
LangChainには、本来だと入力文字数の限界に到達してしまい、処理する事ができない長文を要約できたり、異なる大規模言語モデルを組み合わすことができたり、回答履歴を保持して再度活用できたり、プロンプトの管理を適切にできたりと様々な機能があります。
細かい機能の紹介は省かせて頂きまして、簡単な実装例をここで紹介したいと思います。
template =
"""あなたはライターで{subject}に関して、あまりリテラシーの少ない方々向けにコラムを書くことになりました。
{subject}に関して知識がない方たちが読みたくなるようなキャッチフレーズ例を3つあげてください。"""このようにプロンプトのテンプレートを設計します。
次にLangChainのPromptTemplateを使って次のように定義します。
prompt = PromptTemplate(
template=template,
input_variables=["subject"])
prompt_text = prompt.format(subject="大規模言語モデル")そして実行します。モデルはOpenAIが提供するLLMである「text-davinci-003」を用いてま
すが、APIの使用方法などは割愛させて頂きます。
lm = OpenAI(model_name="text-davinci-003")
print(llm(prompt_text))出力として次のものが得られました。
- 「言語モデルはあなたの話す言葉を理解し、それを使って新しい言葉を創造することができる究極の人工知能技術です。」
- 「言語モデルは、自然言語処理を可能にし、あなたが考えることを文字や言葉に変換することができます。」
- 「言語モデルは、あなたが話している言葉を解釈するだけでなく、様々な言語の共通話語を理解するために開発されています。」
ここでは非常にシンプルな例ではありましたが、大規模言語モデルをコード上で割と簡単に制御できるイメージがなんとなくできたのできたのではないでしょうか。ただこれはあくまで簡単に使用できるようになっただけで、機能を拡張できたわけではありません。次は少し拡張したものをみていきたいと思います。
色々と拡張の幅はありますが、ここでは拡張の例としてChainというメソッドを使用してみたいと思います。大規模言語モデルではモデルにもよりますが、入力テキストの最大数があります。それを超える長いトークン(テキストの最小単位、主に単語と読み替えて頂いて大丈夫です)を処理することは不可能であり、仮に最大数以内であったとしても長い文章では出力の精度が下がる事も考えられます。そこで出てくるのがChainという機能になります。
それでは例として、wikiの「プログラミング」の次の文章をChainを使って要約をしてみたいと思います。この文章はそれほど長くはないのですが、Chainでの処理とその処理の結果がわかりやすいためこちらを例として使用させて頂きたいと思います。文字数としては約900文字ほどです。

「プログラミング」『フリー百科事典 ウィキペディア日本語版』(http://ja.wikipedia.org/)。2023年8月20日15時(日本時間)現在での最新版を取得。
この文章を適切に分割して、Chainを使って要約を作る実装例は次のようになります。
from langchain import OpenAI
from langchain.chains.summarize import load_summarize_chain
from langchain.chains import SimpleSequentialChain
from langchain.text_splitter import TokenTextSplitter
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
max_tokens:int = 100
llm = OpenAI(temperature=0)
text_splitter = TokenTextSplitter(chunk_size=max_tokens, chunk_overlap=20)
summary_chain = load_summarize_chain(llm, chain_type="map_reduce")
promptSubject = PromptTemplate(input_variables=["text"], template="""{text}について要点を3つに絞り箇条書きで要約を書いて下さい
""")
chainSubject = LLMChain(llm=llm, prompt=promptSubject)
overall_chain_map_reduce = SimpleSequentialChain(chains=[summary_chain, chainSubject])
subject = overall_chain_map_reduce.run(text_splitter.create_documents([sample_text]))
細かい実装の説明は省きますが、簡単に説明をしますと、900字の文章を100字ごとに区切って、Map-Reduceという分散処理の仕方を使用して処理をしてます。
出力は次のようになりました。
- Computer programming involves creating algorithms, assessing accuracy, optimizing resource consumption, coding in a programming language, and testing, debugging, and maintaining source code.
- Reverse engineering is the process of solving problems using technical knowledge.
- Hackers are computer experts that perform reverse engineering.
英語で返ってきたので日本語にしてみましょう。
- コンピュータプログラミングは、アルゴリズムの作成、正確さの評価、リソース消費の最適化、プログラミング言語でのコーディング、そしてソースコードのテスト、デバッグ、および保守作業を含む作業です。
- リバースエンジニアリングは、技術的知識を用いて問題を解決するプロセスです。
- ハッカーは、コンピュータの専門家であり、リバースエンジニアリングを行う人々を指します。
なんとなく、それっぽく要点を絞って3つの箇条書きで出力してくれたような印象はありますね。
非常にざっくりとした紹介にはなってしまいましたが、このように大規模言語モデルを制御し拡張して様々な開発をすることが可能となっており、日々新しい技術が開発されています。こういった技術やベクトル化の技術を利用して現在弊社では、大学の研究所と共同での開発もすでに進めています。技術の進化が非常に早く、常にバージョンが更新され新しいアプリやサービスが開発されつつある状況にあり、まだまだ多くのビジネスチャンスが眠っている可能性が多くあります。興味を持っていただけましたらぜひ弊社へご相談くださいませ!こういったサービスの開発をしたいというエンジニアも随時募集しております!
⇨案件のお問合せ
〜その他弊社関連の情報〜
採用ページ
弊社公式Twitter(X)
弊社オリジナルキャラクターバレアルマンTwitter(X) Twitterのフォローもお待ちしてます!
はい、ということでブログの締めは、せっかくなのでChatGPTに行なってもらいましょう。

大規模言語モデルは、人工知能の分野で最も革新的な技術の1つです。データサイエンティストたちは、膨大な量のデータを使用して、コンピューターが人間のように話すことができるようにするためのモデルを構築しています。この技術は、私たちの生活をより便利で豊かにするだけでなく、科学的研究やビジネスにも革命をもたらす可能性があります。大規模言語モデルは、私たちがこれまでに経験したことのない未来を切り開く魔法の鍵となるでしょう。
最後まで読んで頂き、誠にありがとうございました。
(OpneAIは「魔法」が好きなのかも・・・?)









